
In questa lezione vedremo una caratteristica molto interessante per gli sviluppatori Java o, in generale, su linguaggi basati sullo di una JVM: la possibilità di incorporare un database a grafo direttamente nell'applicazione.
Ciò è particolarmente interessante quando il volume di dati da trattare non raggiunge dimensioni ragguardevoli, quando l'applicazione è in hosting (generalmente lo spazio occupato dall'applicazione è gratuito o ha un costo fisso rispetto ai servizi di storage) o in generale per semplificare il deploy di un'applicazione che ha bisogno di storage a grafo.
Naturalmente ciò ha un prezzo di cui bisogna essere consapevoli: scegliendo di utilizzare il database in questa modalità (embedded), Neo4j viene eseguito nel processo della nostra applicazione, con tutto ciò che questo comporta. Ad esempio, in caso di crash della nostra applicazione, anche Neo4j verrà terminato, e viceversa. Inoltre, la memoria stessa è condivisa.
Setup
Per prima cosa aggiungiamo Neo4j al nostro progetto nel nostro IDE preferito. Sebbene esistano varie procedure, noi vedremo come utilizzare Maven in NetBeans.
Creiamo un progetto Maven:

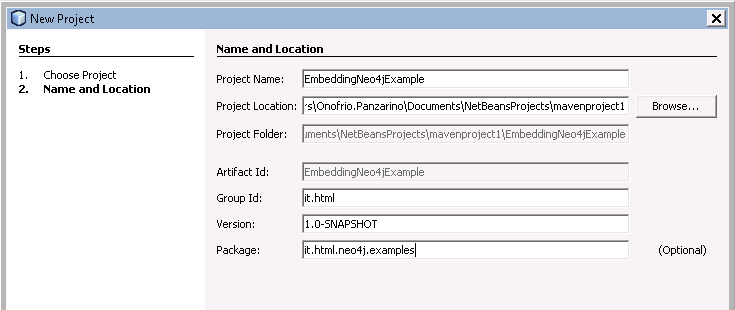
Modifichiamo il file pom.xml e aggiungiamo la dipendenza Neo4j. Rispetto alla dipendenza dal driver Java, la differenza è che qui non abbiamo una dipendenza da neo4j-java-driver ma da neo4j:
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j</artifactId>
<version>3.2.5</version>
</dependency>Ora, mentre Maven scarica e aggiorna le numerose dipendenze alla nostra applicazione, possiamo introdurre il datatabase nel codice dell'applicazione.
final GraphDatabaseService db = new GraphDatabaseFactory()
.newEmbeddedDatabase(new File("/var/data/example.graphdb"));
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
db.shutdown();
}
});Analogamente all'oggetto di tipo Driver visto in precedenza, la classe GraphDatabaseService è thread-safe: per questo motivo, è necessario creare una sola istanza e tenerla come singleton in tutto il ciclo di vita dell'applicazione, anche perché non è possibile creare due database contemporaneamente sugli stessi file. Nel nostro esempio il database aperto si trova nella cartella example.graphdb.
Nella seconda riga di codice abbiamo introdotto un hook per assicurare la corretta chiusura del database, con il rilascio di tutte le risorse allocate e la chiusura di tutti i file. In caso di applicazione JEE, o in generale di applicazione creata in un framework, ovviamente bisogna assicurare lo shutdown in modo opportuno (ad esempio al destroy di una Servlet).
Transazioni
Le operazioni che abbiamo visto finora in Cypher possono essere effettuate tramite le API Java. Ad esempio, la creazione di un utente che abbiamo già visto nelle lezioni precedenti, qui diventa:
try (Transaction tx = db.beginTx()) {
// (1)
Node test2 = db.createNode();
test2.addLabel(Label.label("User"));
test2.setProperty("name", "test2@html.it");
// (2)
Node testers = db.createNode();
testers.addLabel(Label.label("Group"));
testers.setProperty("name", "Testers");
// (3)
Relationship relationship
= testers.createRelationshipTo(test2,
RelationshipType.withName("CONTAINS"));
relationship.setProperty("created", System.currentTimeMillis());
tx.success();
}Con questo codice molto procedurale, dentro una transazione (beginTx) abbiamo:
- creato un nodo (test2) con il metodo
createNode, assegnato una label conaddLabele una proprietà consetProperty; - creato un secondo nodo (Testers);
- infine, creato una relazione, con il metodo
createRelationshipTotra essi, di tipoCONTAINS.
Naturalmente non è leggibile come Cypher ma è molto efficiente, soprattutto in caso di operazioni massive dentro cicli. Fortunatamente, però, con questa API è possibile eseguire anche query Cypher, come vediamo in questo esempio (analogo a quello già visto in una lezione precedente):
try (Transaction tx = db.beginTx()) {
Map<String, Object> parameters = new HashMap<>();
parameters.put("name", "test@html.it");
Result r = db.execute("MERGE (n:User {name: {name}}) " +
"ON CREATE SET n.created_at = TIMESTAMP() " +
"RETURN id(n) as id, n.created_at AS ts",
parameters);
while(r.hasNext()) {
Map<String, Object> record = r.next();
System.out.printf("Node %d created at %d",
record.get("id"), record.get("ts"));
}
tx.success();
}Il metodo execute esegue la query in Cypher con i parametri passati nella mappa (parameters). Il risultato è un un iteratore (classe Result) che si può scorrere per ottenere i risultati restituiti dal server, nel ciclo while, e stamparli in console.
Per i dettagli sull'API, rimandiamo al Javadoc ufficiale che contiene anche diversi snippet per mostrare l'utilizzo delle classi. Spendiamo invece qualche parola su un framework molto interessante che si può usare in questo contesto.
Traversal Framework
Questo framework, presente sin dalle prime versioni di Neo4j, ben prima che fosse introdotto Cypher, era un tentativo di introdurre uno stile di programmazione dichiarativo nel problema della visita del grafo. Oggi possiamo vederla come un'alternativa a Cypher ad alte prestazioni. Ovviamente il problema è che funziona solo con l'API Java. I punti componenti più importanti di questo framework sono:
- Expanders: indicano quali nodi visitare. Nella maggior parte dei casi andiamo ad indicare quali relazioni si devono attraversare e in che verso.
- Evaluators: definiscono il comportamento da adottare mentre si visita un certo nodo (se bisogna includerlo nel risultato e se bisogna andare avanti nella ricerca).
- Order: depth-first o breadth-first.
Non possiamo dilungarci con una trattazione esaustiva (rimandiamo alla guida ufficiale), quindi proponiamo direttamente un esempio di ricerca tramite questo framework. Ipotizziamo di avere un database di aeroporti, connessi dai voli diretti tra essi. Il blocco seguente trova tutte le soluzioni di viaggio, composte da uno o più voli, per andare da uno qualsiasi di due aeroporti (Ciampino o Fiumicino) ad un terzo (Venezia).
StringBuilder output = new StringBuilder();
try (Transaction tx = db.beginTx()) {
Label airport = Label.label("Airport");
Node venezia = db.findNode(airport, "name", "VCE");
Node fiumicino = db.findNode(airport, "name", "FCO");
Node ciampino = db.findNode(airport, "name", "CIA");
for (Path solution : db.traversalDescription()
.breadthFirst()
.relationships(RelationshipType.withName("HAS_FLIGHT_TO"),
Direction.OUTGOING)
.evaluator(Evaluators.pruneWhereEndNodeIs(venezia))
.traverse(fiumicino, ciampino)) {
output.append(solution).append("\n");
}
}
System.out.println(output);In questo codice, vengono inizialmente cercati i tre nodi utilizzati come punti di partenza e arrivo (findNode), quindi viene effettuato il Traversal:
- effettuando una ricerca breadth first;
- indicando le relazioni da attraversare (
relationships). Si tratta di un metodo compatto per indicare un expander; - l'
evaluatorche specifica di fermarsi quando il nodo di arrivo è proprio Venezia; - infine facendo iniziare l'attraversamento del grafo a partire dai due nodi di partenza (
traverse).
Il risultato è un oggetto Traverser che può essere iterato come insieme di Path tra nodi. In questo esempio vengono semplicemente stampati in output.
