
In genere, siamo abituati a pensare che il computer, da solo, non sappia fare nulla. I linguaggi di programmazione ci permettono di istruirlo nello svolgere procedimenti complessi, ma pur sempre guidato passo passo da noi. Esistono tecniche però che mirano a dotare una macchina
della possibilità di "imparare" da set di dati, autoistruirsi al fine di risolvere problemi: tale tecniche appartengono ad un ramo dell'intelligenza artificiale, conosciuto come machine learning.
L'aspetto più rilevante del machine learning consiste nella possibilità di risolvere problemi senza scrivere alcun codice che ne implementi la soluzione:
imparerà la macchina a farlo partendo dai dati da noi forniti.
Fondamentali per la riuscita dei procedimenti di machine learning sono due fattori: l'algoritmo impiegato per la fase di autoapprendimento (detta training) e l'insieme dei dati utilizzati. L'algoritmo non sarà dedicato ad un tipo specifico di problema: si potrà, ad esempio, usare il medesimo per risolvere un problema di matematica finanziaria o di biologia marina, purchè esso possa utilizzare allo stesso modo i dati usati per il training.
I campi di applicazione del machine learning sono i più vari, e queste tecniche vengono spesso usate per risolvere problemi di classificazione: analisi dei mercati finanziari, comunicazione pubblicitaria mirata al cliente, riconoscimento di pattern, previsioni in ambiti vari e molto altro.
Categorie di algoritmi
Esistono moltissimi algoritmi per il machine learning, perciò il primo problema consiste nell'individuare quelli adatti al nostro caso.
Tanto per iniziare con una prima forma di classificazione, si consideri che esistono due grandi famiglie di algoritmi, sebbene non siano le uniche:
- i supervised algorithms (algoritmi di apprendimento supervisionato) prevedono che la fase di apprendimento abbia a disposizione una base di conoscenza, ovvero un insieme di dati in input categorizzati in modo corretto. Ad esempio: abbiamo dati finanziari storici che contemplano sia le condizioni ecomiche sia le variazioni di prezzo che tali circostanze hanno indotto su alcuni titoli. Nella fase di training, la macchina potrà quindi "studiare" i dati del problema sapendo già a quale conseguenza hanno portato: un pò come fare esercizi di cui viene fornita già la
soluzione. Il modello realizzato in training potrà essere calibrato con una continua opera di correzione degli errori di valutazione intercorsi; - gli unsupervised algorithms (algoritmi di apprendimento non supervisionato): la macchina imparerà da dati in input non categorizzati, pertanto individuerà relazioni tra essi senza poter
verificare a priori la correttezza del modello.
Un'altra distinzione che può essere operata tra gli algoritmi riguarda i principi su cui basano la tecnica di apprendimento, e questo è uno dei fattori
principali per la scelta dell'algoritmo da adoperare. Ecco alcune delle classi più conosciute:
- algoritmi regression, basati cioè sulla regressione, che mirano ad individuare il modo in cui da variabili indipendenti si possa prevedere il comportamento di
variabili dipendenti, minimizzando l'errore; - algoritmi di clustering, che raggruppano elementi in classi omogenee. Il loro scopo può avere una doppia valenza: da un lato permettono di individuare
gruppi di oggetti accomunati da vari attributi, dall'altro permettono di riconoscere gli outlier, elementi non associabili a gruppi, rivelatori pertanto di
situazioni problematiche o interessanti da studiare; - alberi decisionali: stabiliscono collegamenti tra dati in input, evidenziando percorsi che da condizioni iniziali conducano ad un certo risultato. Creano
strutture flessibili in grado di mostrare esiti ben precisi tanto da essere spesso impiegati in processi di supporto alle decisioni; - algoritmi Bayesiani, basati su considerazioni probabilistiche, alla base delle quali vi è il teorema di Bayes (da cui questi algoritmi prendono il nome). Ottimi per determinare la probabilità di appartenza di un elemento ad una determinata classe, ad esempio per la classificazione della clientela;
- reti neurali: riproducono in modo artificiale (e molto semplificato) il funzionamento del cervello, stabilendo relazioni tra nodi di elaborazione adattiva che svolgono
il ruolo di neuroni. Si dà così vita a grafi che forniscono un modo di operare più vicino alla flessibilità della mente umana che alla rigidità degli
algoritmi informatici. Il loro valore si apprezza particolarmente in casi dove i dati in input sono caratterizzati da forte "rumore" o da una varietà tale che ne
rende difficile la classificazione.
Usare R per il machine learning
Le fasi da seguire per affrontare in questi processi sono più o meno le stesse, indipendentemente dalla tecnologia impiegata, e possiamo così riassumerle:
- scelta dell'algoritmo per la fase di training e definizione di suoi eventuali parametri di configurazione;
- preparazione dei dati: procedimento più o meno oneroso a seconda della loro natura, le trasformazioni e
selezioni necessarie e dagli scopi della ricerca. Possono far parte di questa fase operazioni di normalizzazione (riduzione dei valori ad un certo intervallo),
riduzione del rumore, discretizzazione di variabili continue, etc.; - suddivisione dei dati in training set (per la fase di apprendimento) e test set (per la verifica del modello prodotto in fase di training);
- fase vera e propria di training;
- test del modello prodotto mediante il test set.
Tali fasi possono essere ripetute più volte nel tentativo di migliorare l'accuratezza del modello cambiando algoritmo o modulandone diversamente i parametri.
Esistono molti package per il Machine Learning in R, alcuni basati su un singolo algoritmo, altri che ne raggruppano diversi:
tutti comunque potranno essere importati con le funzioni install.packages e library, come già visto:
install.packages(nome package)
library(nome package)Noi faremo uso di caret che già dal suo nome completo, Classification And Regression Training,
illustra la sua completezza includendo sia strumenti di classificazione sia di regressione. Il pacchetto non si limita a questo ma fornisce tutto il necessario
a sostenere lo sviluppatore nelle varie fasi del processo di machine learning, tra cui:
- visualizzazione: la rappresentazione dei dati è primo passo per prendere contatto con il materiale a disposizione.
Tramite la funzionefeaturePlotsi potranno visualizzare grafici molto differenti tra loro, come il Boxplot:Figura 1. Boxplot con caret (click per ingrandire)

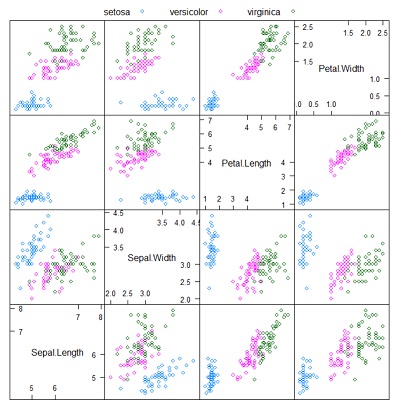
o lo Scatterplot:
Figura 2. Scatterplot con caret (click per ingrandire)
- pre-processamento dei dati con rimozione del rumore, filtraggio, scalamento e via dicendo;
- training con molti modelli disponibili, reclutati da varie
librerie; - misurazione delle performance.
Nella prossima lezione, affronteremo un esempio pratico in cui utilizzeremo caret per il machine learning, mettendo in pratica tutti i concetti visti in questa introduzione.
