Microsoft Azure HDInsight
Microsoft Azure HDInsight è una distribuzione "cloud based" di Apache Hadoop, framework open source che offre supporto per applicazioni distribuite e che consente l’elaborazione di grandi quantità di dati.
In sostanza, con HDInsight abbiamo una piattaforma Hadoop su Cloud senza dover affrontare spese per l’acquisto e la configurazione dell’hardware: Azure permette di avviare un primo cluster in breve tempo eseguendo tutte le operazioni necessarie automaticamente.
Anche se è possibile attivare un numero indefinito di nodi in qualsiasi momento, saranno addebitate alla sottoscrizione solo le risorse per lo storage e la potenza di calcolo effettivamente utilizzate.
Per la distribuzione di Big Data in Microsoft Azure possiamo scegliere tra cluster Linux o Windows; con Windows è possibile impiegare codice esistente basato sul sistema operativo, incluso .NET, con Linux si possono spostare i carichi di lavoro Hadoop nel Cloud integrando componenti Big Data aggiuntivi eseguibili nel servizio.
Gli sviluppatori hanno l’opportunità di realizzare progetti adottando estensioni per diversi linguaggi di programmazione come C#, Java e .NET (incluse in HDInsight). In sostanza si può creare, configurare, inviare ed effettuare il monitoraggio dei processi di Hadoop senza rinunciare alle proprie preferenze in termini di tecnologie e tool di sviluppo.
La capacità di elaborazione di dati non strutturati o semistrutturati provenienti da diverse fonti consente di gestire stream Web, social media, log registrati dai server, device e sensori. Inoltre possiamo visualizzare e analizzare tutte queste informazioni direttamente in Excel, selezionando HDInsight come origine per i dati di Hadoop.
HDInsight include Apache Storm, una soluzione open source per l’analisi degli stream con la quale elaborare eventi in tempo reale, non appena vengono generati negli ambiti più diversi, dall’IoT alle Web application.
A completare l’offerta è incluso in HDInsight anche un altro progetto Open Source, Apache Spark, che abilita l’esecuzione di applicazioni per l’analisi dei dati direttamente in memoria, anche su larga scala. Con Spark le query possono essere fino a 100 volte più veloci rispetto alle tradizionali interrogazioni operate sui Big Data. Si tratta di una soluzione completa per l’estrazione, la trasformazione e il caricamento dei dati, le definizione di query interattive e batch, lo streaming in tempo reale, il Machine Learning e l’elaborazione grafica sui dati archiviati tramite Microsoft Azure.
Apache Storm in Microsoft Azure HDInsight
Uno dei punti di forza di Apache Storm è l’elaborazione di eventi in tempo reale e dataset di grandi dimensioni: parliamo di una soluzione distribuita e Open Source a "tolleranza di errore", cioè capace di proseguire o riprendere a funzionare anche in seguito a un errore di sistema. Il framework è in grado di riavviare automaticamente i ruoli di lavoro su altri nodi per garantire continuità in caso di errore; Microsoft Azure Storm per HDInsight garantisce tempi di attività del 99.9%, offre il monitoraggio dei cluster e il supporto 24 ore su 24, 7 giorni su 7 per le aziende.
Per fare un esempio, Twitter ha scelto Apache Storm come event processor e lo ha utilizzato per gestire il flusso dei tweet pubblicati sulle timeline.
In Microsoft Azure Apache Storm elimina gli oneri legati alla necessità di comprare hardware e configurare il software, la piattaforma esegue tutte le operazioni richieste automaticamente in modo da essere operativi in pochi minuti e iniziare a distribuire Storm senza costi iniziali. Si possono inoltre adottare strumenti di sviluppo largamente diffusi come per esempio Java e C# avvantaggiandosi dell’integrazione predefinita con un ambiente integrato per il coding come l’IDE Visual Studio, anche per il debugging.
Distribuire un cluster Apache Storm
Come anticipato, la distribuzione di un cluster Apache Storm in Microsoft Azure HDInsight è un’operazione praticamente immediata. Si inizia con l’accesso al portale Azure e, tramite il motore di ricerca interno della sezione "Esplora >" si cerca la voce "Cluster HDInsight" . Una volta raggiunta la schermata della sezione HDInsigth clicchiamo su "Aggiungi".
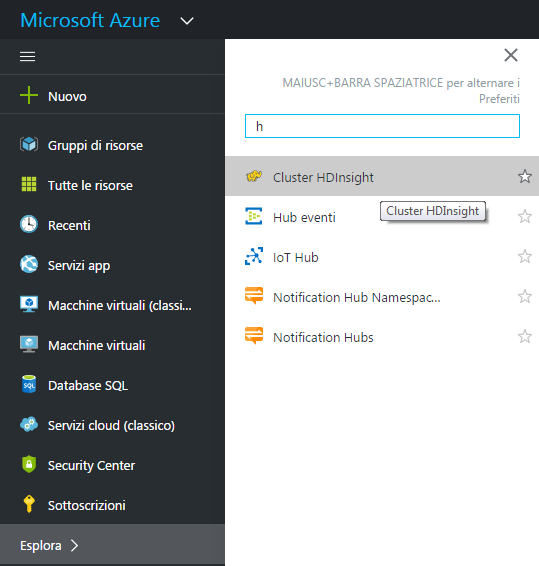
Fatto questo il passaggio successivo richiede di dare un nome al nuovo cluster, "htapp" nel nostro esempio, per poi scegliere il tipo di cluster che nel caso specifico sarà "Storm".
Non siamo vincolati alle sole piattaforme Windows, perciò possiamo scegliere Linux come alternativa se vogliamo adottarlo come ecosistema per la nostra distribuzione HDInsight.
Per ciascun cluster si deve selezionare un "tier" (livello del cluster) sulla base del quale vengono messe a disposizione le funzionalità a completamento del servizio (aggiornamenti, patch, scalabilità dei nodi e prerogative per l’amministrazione).
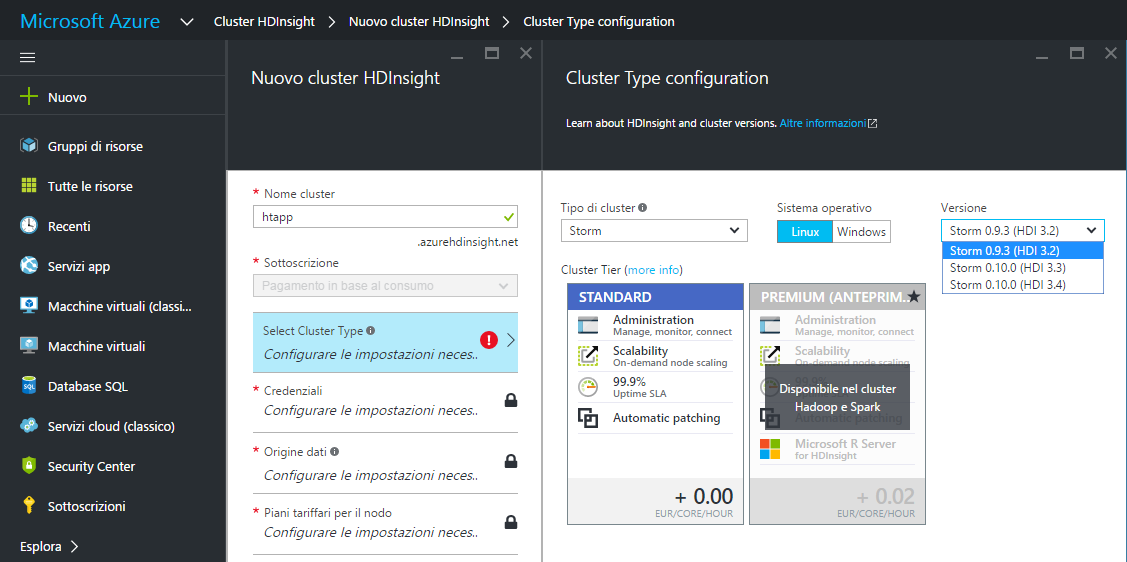
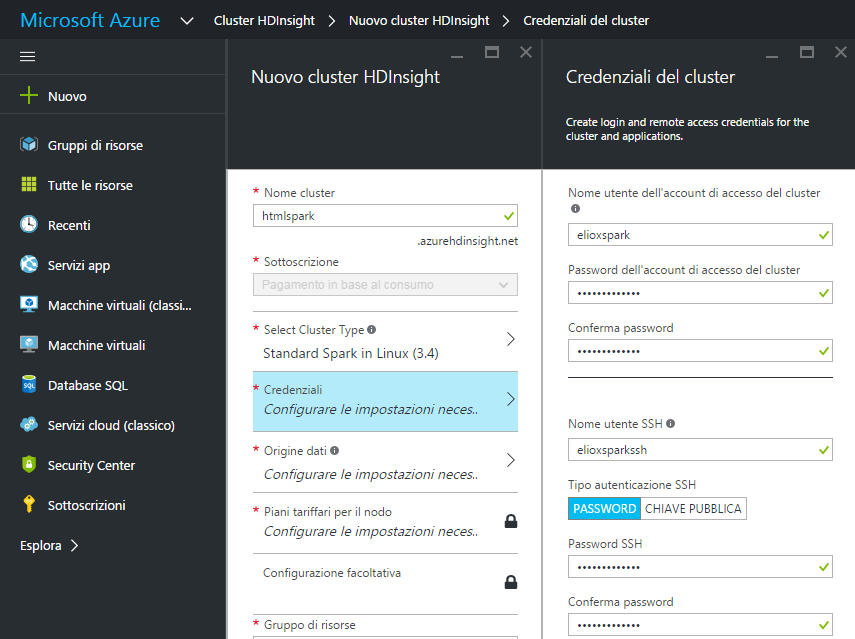
Lo step successivo richiede di associare delle credenziali al cluster, dobbiamo quindi definire un nome utente per l’account di accesso del cluster, "eliox" nel nostro esempio, e una password da confermare. Stesso discorso per quanto riguarda l’accesso sicuro da remoto tramite SSH, per il quale è possibile scegliere due tipologie di autenticazione: "password" o "chiave pubblica".
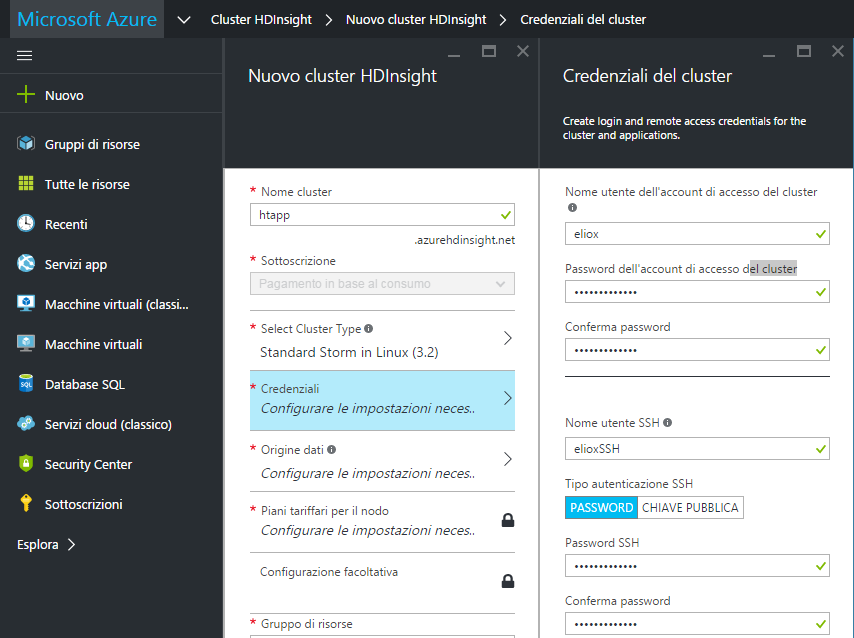
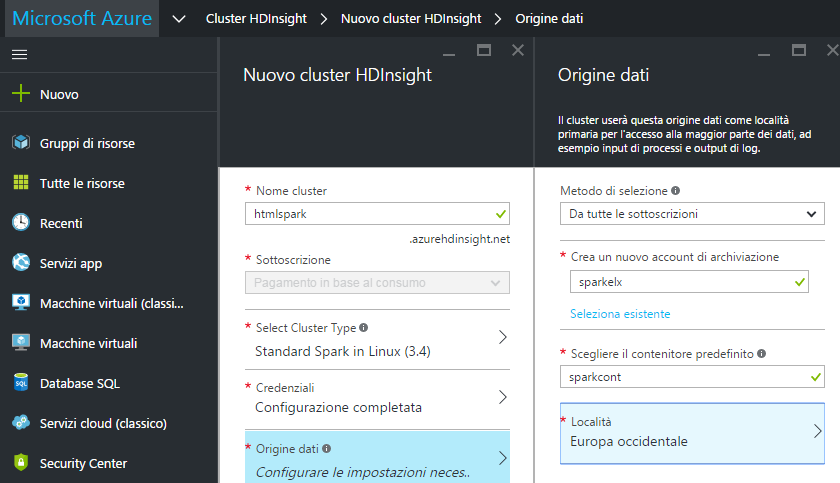
Stabilite anche le credenziali per l’accesso si passa alla definizione dell’origine dei dati, che sarà utilizzata dal cluster come località primaria per la maggior parte dei dati, tra cui gli input dei processi e gli output di log. Non ci rimane che creare un nuovo account di archiviazione, "elx" nel nostro esempio, scegliere un contenitore predefinito associando ad esso un nome (ad esempio "elioxcont") e selezionare una località geografica per la collocazione dell’origine dei dati. Fatto questo basta cliccare su "Seleziona" per confermare i dati indicati.
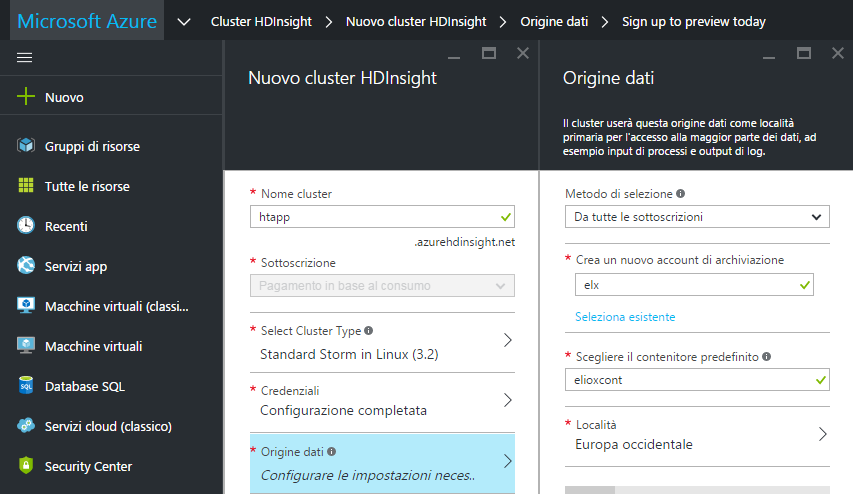
La successiva scelta del piano tariffario da associare al cluster dipende dalle esigenze legate al proprio progetto, esso varia però a seconda del numero di nodi da associare al cluster, che di default sono 4, al numero dei core, alla quantità di memoria RAM, al numero di dischi e dello spazio su SSD locale per l’archiviazione.
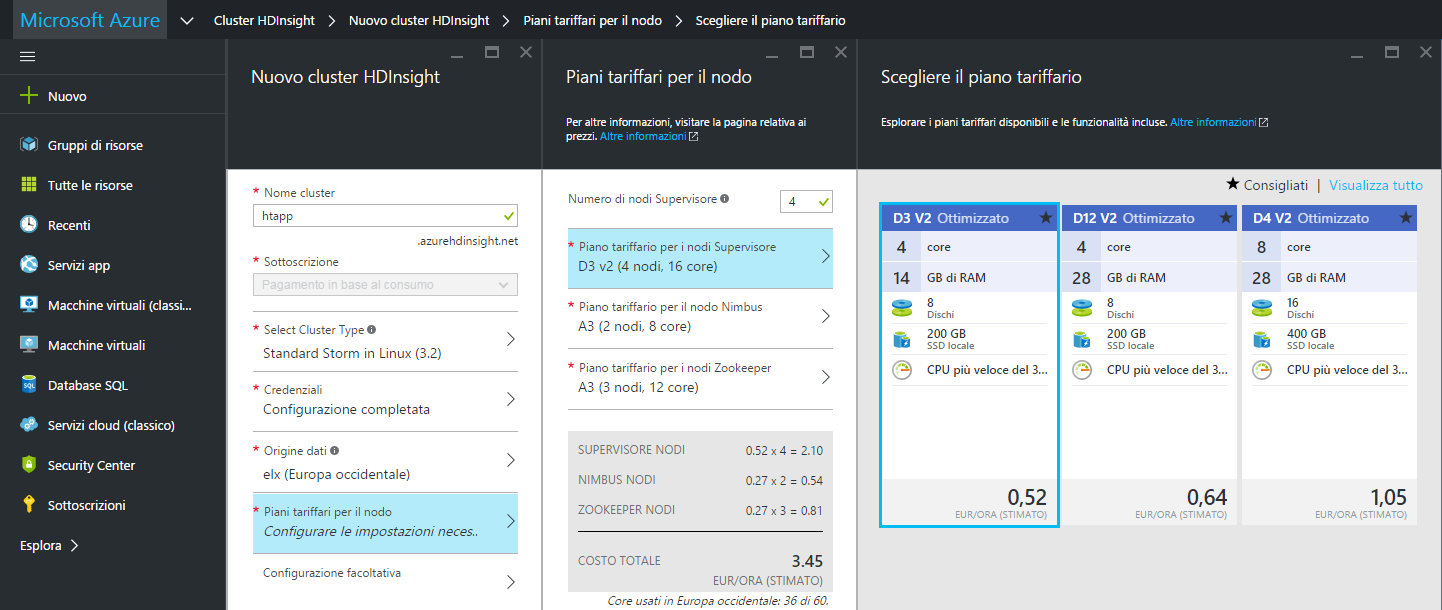
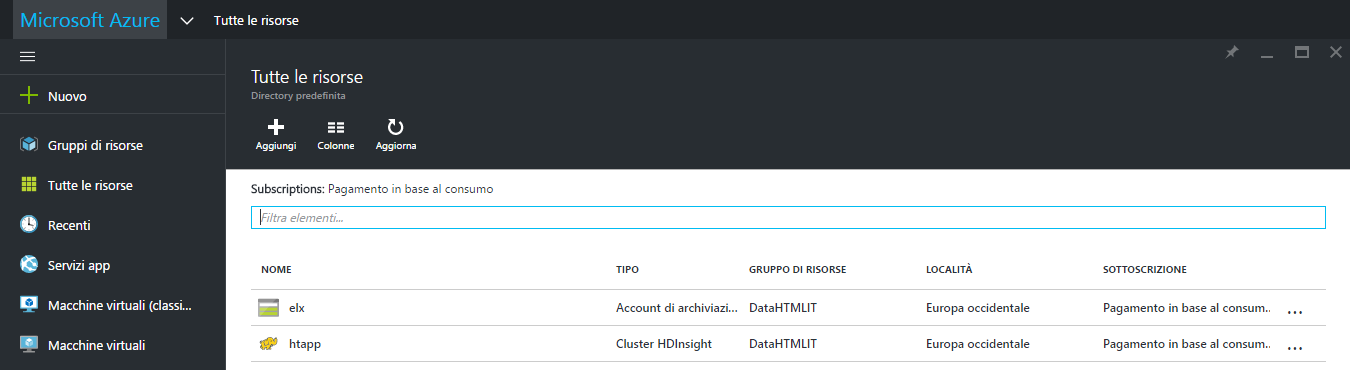
Una volta scelto il piano tariffario ottimale si deve decidere a quale gruppo di risorse associare il cluster creandone uno nuovo o optando per un gruppo già esistente, ad esempio "DataHTMLIT" creato per le precedenti lezioni, e cliccare su "Crea" per distribuire il cluster di HDInsight che, alla fine del processo, risulterà elencato tra le risorse presenti nel gruppo di appartenenza.
Apache Spark in Microsoft Azure HDInsight
Apache Spark è un framework open source ad elevate prestazioni per l’elaborazione dei dati con il quale effettuare query su Big Data ed eseguire applicazioni per l’analisi su larga scala, tecnicamente si tratta di una soluzione basata su un motore di calcolo residente in memoria per l’elaborazione parallela delle informazioni che, quando necessario, è in grado di salvare permanentemente su disco.
In fase di elaborazione gestire i dati direttamente in memoria può offrire velocità anche 100 volte superiori rispetto al modello classico basato sullo storage fisico, soprattutto in attività come per esempio l’ETL (Extract, Transform, Load), la formulazione di query interattive, l’elaborazione grafica e l’esecuzione di batch. Apache Spark può essere distribuito in modo semplice tramite Microsoft Azure, senza dover acquistare hardware o procedure di configurazione complicate e con la possibilità d’integrare il framework con strumenti di terze parti per la business intelligence.
Spark su HDInsight rappresenta una soluzione ottimale per velocizzare le applicazioni Big Data intensive ed effettuare praticamente in tempo reale operazioni quali il rilevamento delle frodi informatiche, l’analisi del clickstream per monitorare i comportamenti e i percorsi degli utenti in una piattaforma rilevandone abitudini e preferenze, gestire avvisi finanziari, elaborare informazioni raccolte tramite telemetria da sensori, e dispositivi IoT, raccogliere e analizzare i dati dei social media e device mobili o eseguire il monitoraggio delle attività di rete.
Con Spark per HDInsight vengono utilizzati Microsoft Power BI, Tableau, Qlik e SAP Lumira per analizzare ed esplorare i Big Data in modalità visuale, indipendentemente dallo loro quantità. Per gli sviluppatori è disponibile il supporto a diversi linguaggi tra cui Java, Python nonché API Scala; si possono realizzare applicazioni sfruttando oltre 80 operatori con cui iterare i dati. Nei cluster Spark sono poi precaricate librerie Python per il Machine Learning.
I notebook Jupyter (IPython) o Zeppelin permettono di effettuare analisi interattive tramite Scala, Python o SQL creando narrazioni in grado di combinare codice in real time, statistiche e testi con cui esporre la storia dei dati gestiti.
Creare cluster Spark con HDInsight in Microsoft Azure
Per creare un cluster Spark con HDInsight su Microsoft Azure è disponibile una procedura per molti versi simile a quella già adottata per la distribuzione di un cluster Storm. Anche in questo caso, dopo l’accesso al portale, cerchiamo la voce "Cluster HDInsight" e nella schermata che otteniamo clicchiamo su "Aggiungi". Il prossimo passaggio richiede di dare un nome al nuovo cluster, "htmlspark" nell’esempio, per poi selezionare il tipo di cluster che deve essere creato: "Spark".
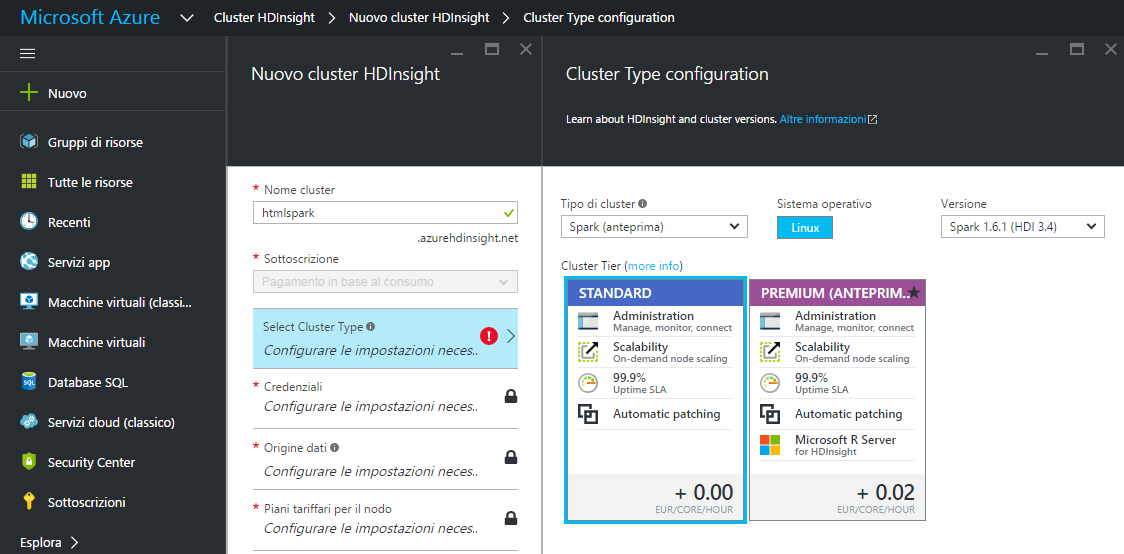
In questo caso abbiamo a disposizione Linux come piattaforma per il cluster HDInsight. Possiamo procedere alla scelta del "tier" e definire le credenziali di accesso al cluster indicando un nome utente per l’account, "elioxspark" nel nostro esempio, e una password per il login. Dovremo poi ripetere l’operazione per l’accesso tramite SSH scegliendo tra le due tipologie di autenticazione: "password" o "chiave pubblica".
Passando alla definizione dell’origine che il cluster adotterà come località per l’accesso ai dati, si deve innanzitutto creare un nuovo account di archiviazione, "sparkelx" nell’esempio, per poi definire un contenitore di default chiamandolo ad esempio "sparkcont", e scegliere una località geografica per l’origine dei dati. Cliccando su "Seleziona" le impostazioni vengono confermate.
Anche in questo caso, una volta stabilito il piano tariffario più congeniale al nostro, passiamo ad associare il cluster ad un gruppo di risorse scegliendo tra un gruppo preesistente, come il già utilizzato "DataHTMLIT" , e cliccando sul pulsante "Crea" per generare il cluster Spark di HDInsight. Una volta creata, questa risorsa risulterà elencata tra quelle presenti nel gruppo scelto dall’utilizzatore.