
I rami (branch o più estesamente "ramificazioni") vengono utilizzati in Git per l'implementazione di funzionalità tra loro isolate, cioè sviluppate in modo indipendente l'una dall'altra ma a partire dalla medesima radice. Strutturalmente il ramo predefinito di un progetto gestito tramite il DVCS è il master che viene generato quando si crea un repository; sarà poi possibile ricorrere ad ulteriori diramazioni dedicate a features differenti per poi inserirle nel master, tramite procedura di merging, quando complete.
Cosa sono in rami in Git
Si ipotizzi di dover lavorare ad un progetto specifico come per esempio la documentazione a corredo di un software. Una volta completata la bozza iniziale quest'ultima dovrà passare il vaglio della revisione per poter essere approvata e pubblicata. Se lo sviluppo dell'applicazione rimane attivo nel tempo si presenterà certamente l'esigenza di effettuare degli aggiornamenti anche a carico della documentazione.
Non sempre però le necessità di aggiornamento si presentano dopo che la revisione della prima bozza viene completata. Motivo per il quale si potrebbe avere l'esigenza di disporre di una versione modificata con i nuovi dati, pur conservando quanto prodotto fino a quando sono stati apportati i cambiamenti richiesti dall'evoluzione del progetto in corso. In sostanza si avranno due versioni distinte della medesima bozza.
E' possibile comprendere meglio il funzionamento di questo meccanismo facendo riferimento alle procedure utilizzate da Git per l'archiviazione delle informazioni, si ricordi infatti che l'applicazione non è stata concepita per memorizzare dati sulla base delle modifiche che hanno subito, ma per salvarli come degli snapshot (istantanee) disposti in sequenza. Si pensi per esempio alla dinamica dei commit, nel momento in cui ne viene eseguito uno verrà generato un oggetto omonimo che punta allo snapshot del contenuto allocato.
I puntatori dei commit rivelano una disposizione gerarchica per la quale il commit iniziale non avrà alcun commit genitore, come accade per il master che è il ramo originario generato di default, un commit successivo avrà un solo genitore (quello iniziale), mentre il commit risultate dal merging di più diramazioni avrà anche più genitori.
Il ruolo dei puntatori
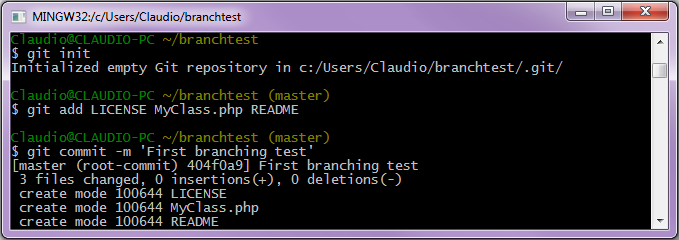
Per proporre un esempio sul funzionamento delle ramificazioni è possibile creare una nuova cartella progetto, denominata branchtest, nell'area di lavoro. Tale directory conterrà 3 file.

Seguendo la classica dinamica del versioning si dovrà procedere nell'ordine all'inizializzazione del repository, allo spostamento di tali risorse nell'area di staging e, infine, al commit.
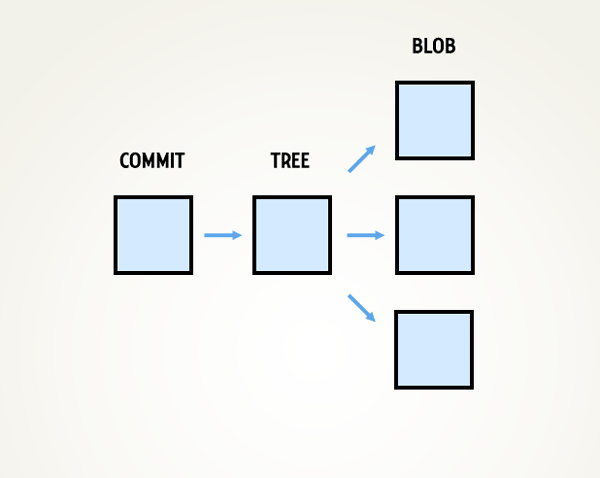
Ora si analizzino gli effetti di queste operazioni nella directory di Git. In pratica, al momento del commit il DVCS si occuperà di restituire un checksum della cartella del progetto che, in questo caso, assumerà anche il ruolo di directory radice; verranno quindi memorizzati 3 differenti oggetti (detti "blob") che entreranno a far parte del repository, inoltre, verrà generato un ulteriore commit dell'oggetto contenente le informazioni relative ai metadati e un puntatore, indicante la radice dell'albero ("tree") dal quale si dirama il progetto, che consentirà il recupero dello snapshot prodotto dal commit dell'utilizzatore.
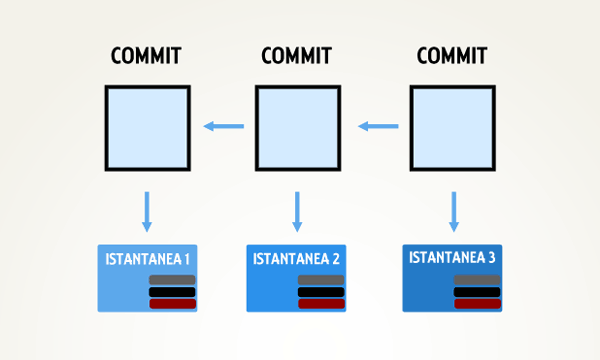
Un commit eseguito successivamente per certificare una modifica sarà a sua volta dotato di un puntatore a quello che lo ha preceduto e così via, ne consegue che un ramo non è altro che un puntatore ad uno dei commit eseguiti.
Creazione dei rami
Continuando a lavorare sul progetto branchtest si potrà creare un nuovo ramo tramite il comando git branch seguito dal nome di quest'ultimo, ad esempio formulando l'istruzione:
$ git branch newbranchgit branch segue la logica proposta alla fine del paragrafo precedente generando un puntatore indirizzato verso il commit corrente; Git terrà traccia delle istantanee e del loro ordine risalendo la catena dei commit, utilizzerà poi un proprio puntatore (HEAD) per capire su quale ramo si sta attualmente lavorando. L'utilizzatore dovrà spostarsi volontariamente su un nuovo ramo dopo averlo generato, git branch infatti ne permette la creazione ma non effettua automaticamente il reindirizzamento ad esso.
Il comando che permette ad HEAD di puntare su un nuovo ramo reindirizzando su di esso anche l'utente è git checkout seguito dal nome del ramo stesso:
$ git checkout newbranchSi ipotizzi ora di effettuare un nuovo commit, per esempio dopo aver modificato il file README del progetto sul quale si sta lavorando:
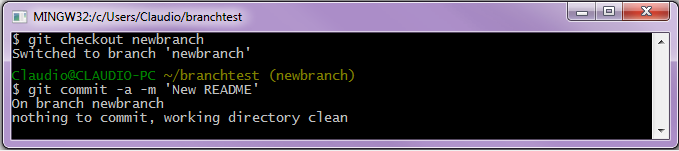
A differenza di quanto accade con git branch il commit sposterà in avanti il ramo a cui punta HEAD, nel caso specifico il ramo newbranch avanzerà di una posizione mentre master punterà comunque al commit nel quale ci si trovava prima del precedente git checkout. Lanciando quindi:
$ git checkout masterHEAD arretrerà fino a puntare su master e i file presenti nella directory di lavoro saranno quelli associati a quest'ultimo e non presenteranno le modifiche eseguite per i nuovi rami; in sostanza, facendo riferimento all'esempio proposto in precedenza, il progetto potrà essere implementato in modo differente rispetto alla direzione che era stata decisa nel momento in cui è stato aggiunto il ramo newbranch.
Ne consegue che, dato che ora il puntatore di Git si trova su master, un eventuale nuovo branch che dovesse essere creato da questa posizione sarà indipendente e parallelo a newbranch fino a quando l'utilizzatore non dovesse optare per una fusione.
Se vuoi aggiornamenti su Development inserisci la tua email nel box qui sotto:
