
Creare progetti Git, importare o clonare?
Per lavorare con GIT dobbiamo creare un area di lavoro, un progetto, ovvero un ambiente in cui vivano le versioni dei nostri file. Abbiamo a disposizione due modalità per creare un progetto con Git:
- importazione
- clonazione
Indipendentemente dalla procedura adottata, una volta creato un progetto lo si potrà tracciare istantanea per istantanea effettuando di fatto quella che è la funzione principale dell'applicazione, il versioning.
Init: creare un nuovo progetto Git (o "importare")
Creare un nuovo progetto Git significa trasformare la directory che ospita il nostro codice in un repository per il versioning. Nel gergo di Git questa operazione si chiama import e si svolge piuttosto semplicemente. Occorre solo spostarsi all'interno della directory che ci interessa e lanciare il comando init, in questo modo:
$ git initNell'immagine seguente vediamo un esempio in cui creiamo nuova directory (mkdir project-htmlit), ci spostiamo al suo interno (cd project-htmlit) e lanciamo l'inizializzazione.
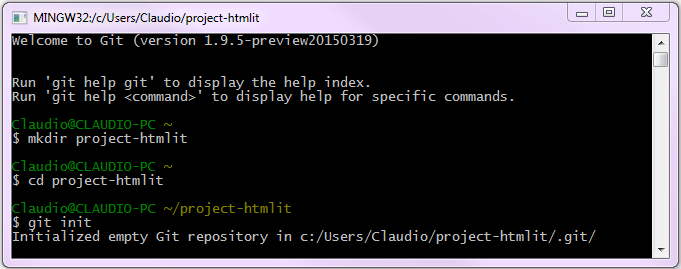
Una volta inizializzato il progetto con git init, troviamo nella nostra directory una sottodirectory già popolata chiamata .git. È la cartella che contiene l'intero repository e la sua struttura: se volessimo creare una copia di salvataggio del nostro repository sarebbe sufficiente duplicare la directory .git.
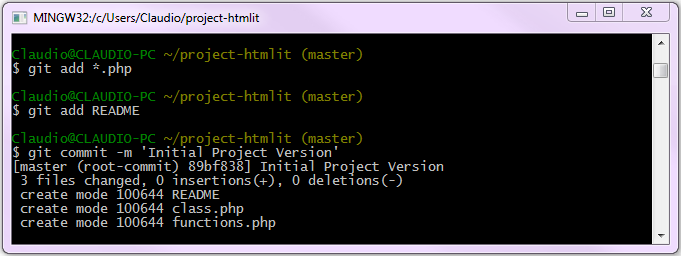
Siamo pronti per effettuare il primo commit a testimonianza del lancio del progetto corrente. I commit eseguiti durante l'attività di controllo di versione certificheranno tutti gli interventi effettuati a carico del progetto stesso. Nel caso dell'esempio proposto di seguito, la modifica al repository consisterà nell'aggiunta di una serie di file ".php", di un file denominato README e nella generazione del primo commit:
$ git add *.php
$ git add README
$ git commit -m 'Initial Project Version'È bene precisare che il compito del comando add
git add
staging
index
working tree
git add deve essere eseguito a partire dall'area di lavoro e non dalla directory .git, in caso contrario si riceverà una notifica di errore da parte del sistema, l'utilizzatore avrà comunque la possibilità di invocare più volte tale istruzione prima di quella necessaria per il commit e, quando possibile, di impiegare il carattere "*" per effettuare aggiornamenti dell'indice che riguardino più risorse tramite un singolo statement.
Il commit prevede una sintassi basata sull'istruzione git commit seguita da un messaggio (log message) che descriva lo stato del progetto al momento corrente, nel caso dell'esempio proposto l'opzione -m permette di definire tale descrizione; in pratica git commit non farà altro che caricare i contenuti dell'indice precedentemente aggiornato tramite git add in un commit per la conferma di una modifica a carico del progetto gestito.
Struttura della directory .git
Come anticipato, la sottodirectory .git propone una sorta di "scheletro" del repository inizializzato tramite git init, prima di procedere nella gestione del progetto importato potrebbe essere utile analizzare le caratteristiche dei file e delle cartelle presenti in essa:
| Risorsa | Descrizione |
|---|---|
| hooks | E' la cartella destinata a contenere script personalizzati (hooks |
| info | E' una directory che nativamente presenta il file exclude
versioning
.gitignore
|
| objects | La cartella nella quale vengono archiviati i contenuti per il database. |
| refs | E' la directory in cui reperire i puntatori per gli oggetti dei commit. |
| HEAD | Il file che fa riferimento al ramo di sviluppo del quale è stato eseguito il checkout. |
| description | File non necessario se non si utilizza la piattarfoma GitWeb. |
| config | Il file che presenta le configurazioni per un determinato progetto. |
| index | File che memorizza le informazioni relative allo staging |
Dopo il primo commit .git
COMMIT_EDITMSG
logs
Clonare un repository Git
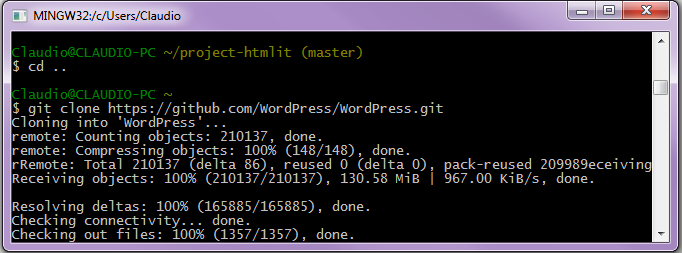
Git rappresenta uno strumento ideale per lo sviluppo in ambito collaborativo, nello stesso modo esso è stato concepito per facilitare la realizzazione di fork (progetti derivati dal sorgente di un'altra applicazione), ecco perché tale DVCS presenta degli strumenti appositamente dedicati alla clonazione di repository preesistenti. Tale operazione prevede una sintassi basata sul comando git clone seguito dall'URL del repository che si intende clonare. Nell'esempio seguente la risorsa duplicata verrà prelevata dalla piattaforma per il code hosting GitHub che basa le procedure per il controllo di versione proprio su Git:
$ git clone https://github.com/WordPress/WordPress.gitNel caso specifico verrà clonato il repository relativo al Blog engine/CMS WordPress, ciò porterà alla generazione di una cartella denominata WordPress che rappresenterà la working tree del progetto e conterrà una propria directory .git.
E' possibile personalizzare il nome della directory di destinazione passando la nuova denominazione scelta ("MyWP" nell'esempio seguente) come secondo argomento dell'istruzione basata su git clone:
$ git clone https://github.com/WordPress/WordPress.git MyWPCome è possibile osservare, dal punto di vista della sicurezza Git permette di appoggiarsi al protocollo HTTPS (HyperText Transfer Protocol over Secure Socket Layer) per la cifratura dei dati trasferiti durante la clonazione.
