
In questo capitolo verrà proposto un esempio molto semplice e nello stesso tempo molto comune per i contesti di elaborazione distribuita: il word counting. Verrà infatti, progettato e implementato un job MapReduce che calcolerà le occorrenze dei termini presenti nel testo di un file.
Progettazione del job MapReduce
Per la progettazione del dovremo predisporre una funzione di tipo map che legga il contenuto di un file e lo inoltri ad una (o più) funzione reduce che provvederà a contare le occorrenze. Di seguito lo schema funzionale di ciò che andremo ad implementare.
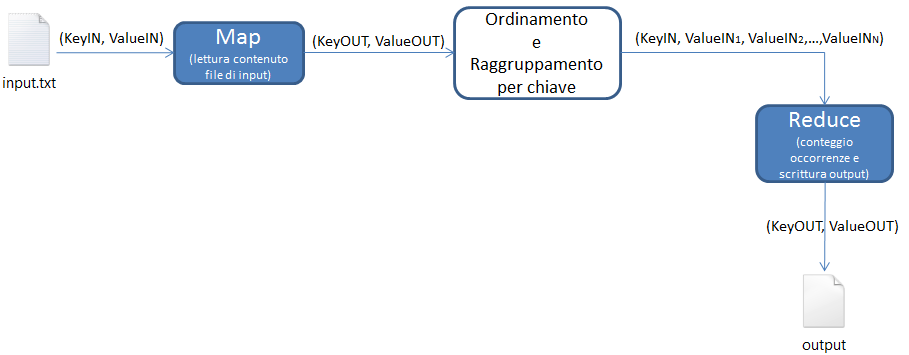
Se conoscessimo bene il framework di Hadoop, potremmo anche pensare di progettare quali siano gli input e gli output delle funzioni map e reduce sulla base dell'elaborazione da svolgere. Ad esempio: siamo sicuri che i valori di input della funzione map sono le righe di testo del file di input pertanto possiamo pensare di utilizzare un oggetto di tipo Text (presente nel framework) per incapsulare il testo letto e utilizzarlo come ValueIN.
Per quanto riguarda la KeyIN, la funzione map() riceverebbe un oggetto che rappresenta la chiave associata al valore rappresentato dall'oggetto Text. Una delle possibilità è quella di scegliere come chiave un valore numerico, (solo questa volta) suggeriamo di scegliere un oggetto di tipo LongWritable (appartenente anch'esso al framework).
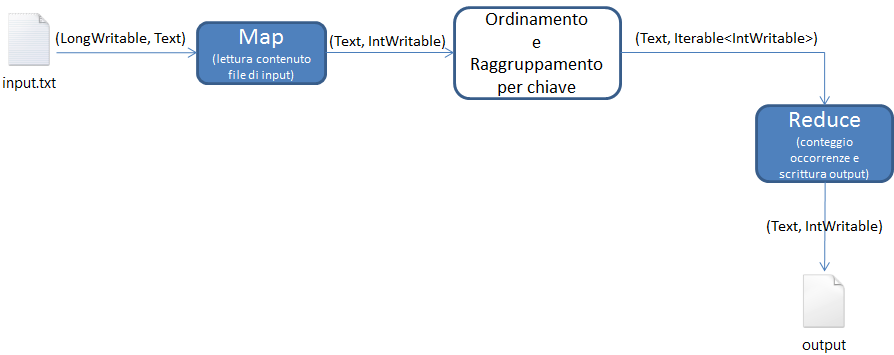
Per quanto riguarda gli output invece, immaginando di voler ottenere come risultato un elenco di termini in cui ogni parola è affiancata dal valore che ne rappresenta le occorrenze, possiamo pensare che la singola parola sia la KeyOUT e che il ValueOUT sia rappresentato dal valore dell'occorrenza. Sulla base di questa considerazione possiamo pensare che la chiave di output sia un oggetto di tipo Text che incapsula una parola letta e che il valore di output sia un oggetto di tipo IntWritable che incapsula un valore iniziale del conteggio dell'occorrenza per la parola corrente (ricordiamo infatti che è un output intermedio e non finale della funzione reduce). Il dettaglio della progettazione della funzione Map risulterebbe quindi quello della figura sottostante:

Con analoghe considerazioni e con la conoscenza dei tipi degli oggetti di output della funzione map, possiamo pensare di progettare gli input e gli output della funzione reduce. Gli output di map, diventano gli input della funzione reduce, quindi dovremmo predisporre oggetti dello stesso tipo. A differenza della funzione map però, in reduce possiamo trovare un elenco di valori di input associati ad una KeyIN.
Il framework permette la gestione di questo dettaglio utilizzando l'oggetto Iterable<valuein> parametrizzato con il tipo di oggetto che abbiamo scelto e che incapsula l'elenco dei valori associati alla KeyIN. Tenendo sempre in considerazione quello che è l'output finale, possiamo pensare che anche gli oggetti di output della funzione reduce siano dello stesso tipo degli oggetti di input. Quindi il dettaglio della progettazione della funzione reduce risulterebbe come in figura:

e il dettaglio funzionale dell'intero job MapReduce risulta essere il seguente:
Sviluppo del job MapReduce
Per lo sviluppo del codice è stato utilizzato Eclipse Java EE Juno. Per gestire un progetto di questo tipo, utilizzeremo inoltre il tool Maven. Dopo aver creato il progetto in Eclipse, ci troveremo di fronte ad un risultato simile a quello in figura:
Grazie all’utilizzo di Maven, possiamo aggiungere la dipendenza di Hadoop configurando il file pom.xml; in particolare, ci assicureremo di impostare repository e dipendenza come segue:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>0.20.2</version>
</dependency>
</dependencies>Una volta configurato pom.xml, possiamo utilizzare il framework. Prima di tutto, creiamo 3 diversi package in src/main/java:
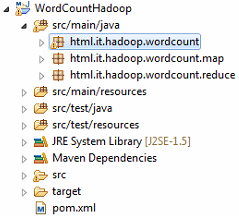
| Package | Descrizione |
|---|---|
| html.it.hadoop.wordcount.map | Conterrà le classi che implementano le funzioni Map |
| html.it.hadoop.wordcount.reduce | Conterrà le classi che implementano le funzioni Reduce |
| html.it.hadoop.wordcount | Conterrà la classe che implementa il Main dell'applicazione |
L’albero progetto risultante dalla creazione dei 3 package descritti sarà il seguente:
Completato lo sviluppo del job MapReduce, nel prossimo capitolo si passerà alla procedura necessaria per l'implementazione della Map.

