
Pre-configurazione del sistema
I prerequisiti per l'installazione di Hadoop su Windows:
- Java JDK (nel caso specifico installeremo la versione 7);
- Impostazione delle variabili di ambiente e di sistema;
Scarichiamo ed installiamo JDK 7. I percorsi di installazione possono essere scelti in modo arbitrario, in questa guida posizioniamo tutto in C:\java\jdk e C:\java\jre7. Successivamente configuriamo le variabili d'ambiente come mostrato nella figura sottostante:
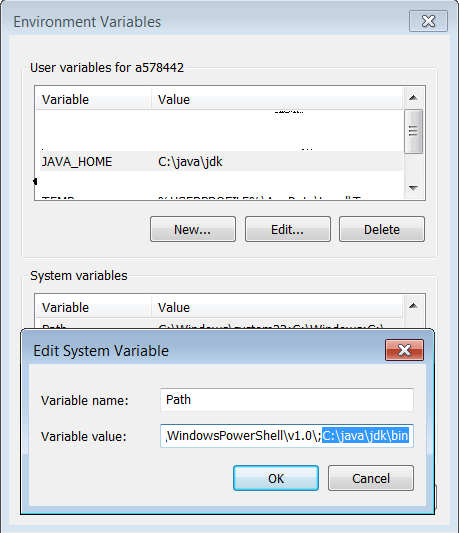
per verificare che la configurazione sia andata a buon fine, eseguiamo il prompt dei comandi e digitiamo l'istruzione java -version che permetterà di visualizzare la versione di Java installata.
Installazione
Dopo aver effettuato il download di Hadoop (ricordiamo che l'archivio è lo stesso scaricato precedentemente), estraiamolo nella directory C:\hadoop. Configuriamo quindi le opportune variabili di ambiente come mostrato nella figura seguente:
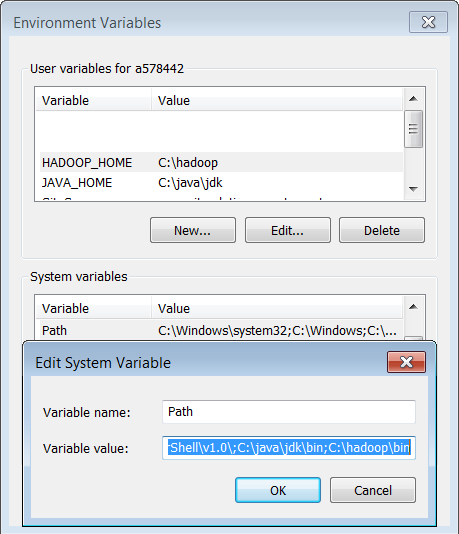
Configurazione
Come mostrato in precedenza, la configurazione consiste nell'editing del file C:\hadoop\etc\hadoop\core-site.xml, all'interno del quale dichiariamo le seguenti properties:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
<description>
Il nome del file system predefinito.Un URI il cui schema e authority determinano l'implementazione del filesystem. Il formato è il seguente : fs.SCHEME.impl nominare la classe di implementazione filesystem. L'authority dell'uri viene utilizzato per determinare l'host, porta, ecc per un filesystem.
</description>
</property>Allo stesso modo, configuriamo il file C:\hadoop\etc\hadoop\mapred-site.xml:
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
<description>
Host e porta su cui viene lanciato il MapReduce job tracker. Se "locale", allora i jobs sono eseguiti in un unico processo come un singolo map e reduce task.
</description>
</property>e il file C:\hadoop\etc\hadoop\hdfs-site.xml:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/data/dfs/datanode</value>
</property>Ultimata la configurazione, procediamo con lo start della nostra installazione. Prima di tutto, quindi, formattiamo il file system lanciando il comando
cd C:\hadoop\bin
hdfs namenode -formatEsecuzione
Una volta superate le fasi di installazione e configurazione, siamo finalmente pronti ad eseguire Hadoop: per farlo digitiamo i seguenti comandi
cd C:\hadoop\sbin
start-all.cmdPossiamo anche accedere all'interfaccia Web di Hadoop Administration digitando nel browser il seguente indirizzo: http://localhost:50070. Analogamente allo start, possiamo arrestare l'esecuzione di Hadoop lanciando il file comando stop-all.
Conclusioni
Ora che abbiamo installato ed eseguito Hadoop sia su Linux che su Windows, nel prossimo capitolo progetteremo e implementeremo un esempio job MapReduce.

