
Ci siamo allenati sinora allo studio delle tecniche per l'interazione con le pagine web. Adesso è arrivato il momento di "impacchettare" il tutto in veri e propri test da eseguire automaticamente. Abbiamo già spiegato cosa intendiamo per test automatici ma riepiloghiamone il senso velocemente.
Testing automatico
I test sono, in parole povere, programmi che verificano il funzionamento di altri programmi. I nostri, nello specifico, saranno test che proveranno funzionalità di pagine web e verificheranno che determinate operazioni, sotto condizioni prefissate, abbiano successo o diano luogo ad un particolare errore. Quest'ultimo aspetto non deve stupire infatti la user experience deve essere di alto livello, sempre, ed una sessione utente è fatta sia di operazioni portate a termine con successo che di errori che devono essere gestiti in maniera indolore e costruttiva per chi usa l'applicazione.
Inoltre, come abbiamo già avuto modo di vedere, alcuni tipi di errori (mappati a livello di programmazione in eccezioni) sono connaturati alla modalità di lavoro in ambito di rete: basti considerare un TimeoutException che scatta nel momento in cui rallentamenti nella comunicazione non permettono alla componente di un'interfaccia di apparire per tempo.
Il fatto che i test siano automatici significa che potranno essere condotti senza l'intervento di un operatore umano con tutti i relativi vantaggi: le macchine infatti potranno effettuarli in qualsiasi ora del giorno e della notte, sempre con le stesse modalità e senza accusare stanchezza o distrazioni.
Pianificare il testing automatico
Per pianificare i test tipicamente si procederà a:
- identificare le azioni utente di cui verificare il funzionamento o, eventualmente, il fallimento;
- associare una funzione di test per ogni azione individuata al punto precedente;
- eseguire tutti i test in sequenza;
- ottenere un report che riassuma i risultati dei test.
Prima di passare alla realizzazione di test con l'utilizzo di strumenti appositi facciamo il punto su alcune metodologie che possono essere utili per organizzarli, renderci produttivi e avvicinarci il più possibile al nostro scopo.
Modalità headless
Abbiamo visto che uno degli aspetti più evidenti dell'automazione dei test consiste nel vedere il browser che si apre e la pagina che si anima come mossa da mani invisibili. Avere questo contatto visivo con il test in esecuzione può essere molto utile ma non sempre indispensabile.
Volendo, infatti, si può ricorrere alla cosiddetta modalità headless in cui tutto il test viene eseguito nella stessa identica maniera ma senza vedere materialmente il browser.
Per attivare tale modalità lo si deve semplicemente comunicare con il driver passandogli l'opzione --headless in fase di configurazione:
from selenium import webdriver
...
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)Il meccanismo delle options, tra l'altro, permette di configurare una serie di altri aspetti del comportamento del driver. In questo esempio l'abbiamo fatto con il browser Chrome ma in realtà è possibile con qualsiasi altro driver. Come si vede infatti ChromeOptions è una classe estratta da webdriver ma al contempo esistono anche FirefoxOptions, EdgeOptions, SafariOptions e via dicendo.
Quando è utile la modalità headless? In tutti quei casi in cui non si ha interesse a vedere il browser che lavora o in cui è necessario lanciare il test attraverso uno script da eseguire prettamente da riga di comando. Viceversa, potrà essere molto utile vedere il browser lavorare quando il test riscontra dei problemi e vogliamo vedere con i nostri occhi in quale punto l'interazione con l'applicazione si interrompe.
Sarà un modo molto veloce per risolvere i bug. Spesso conviene infatti iniziare in modalità standard e quando si ha fiducia nel test creato si passa alla modalità headless.
Provare i selettori CSS
Al di là dei casi in cui si preferirà ricorrere a query XPath o ci si troverà in situazioni così nette da potersi accontentare di individuare elementi per tag o id, si farà presumibilmente uso di selettori CSS. Un ottimo compromesso tra flessibilità e semplicità.
A volte però bisogna lanciare il test più volte prima di poter "azzeccare" la combo di selettori CSS che ci porta più vicini all'obiettivo. Un modo può essere quello di accedere alla console per sviluppatori interna ai browser in cui si può interagire con gli elementi della pagina. Per fare ciò si deve entrare nel set di strumenti per sviluppatori che il browser offre (da menu o semplicemente con l'ispezione di una componente) e nella console utilizzare l'oggetto document per eseguire delle query.
Si tratta di un oggetto JavaScript ma ciò non deve preoccuparci. Sarà sufficiente inserire la query CSS come argomento del metodo querySelectorAll che restituirà tutti gli oggetti rispondenti a quel percorso.
Si osservi la figura seguente:
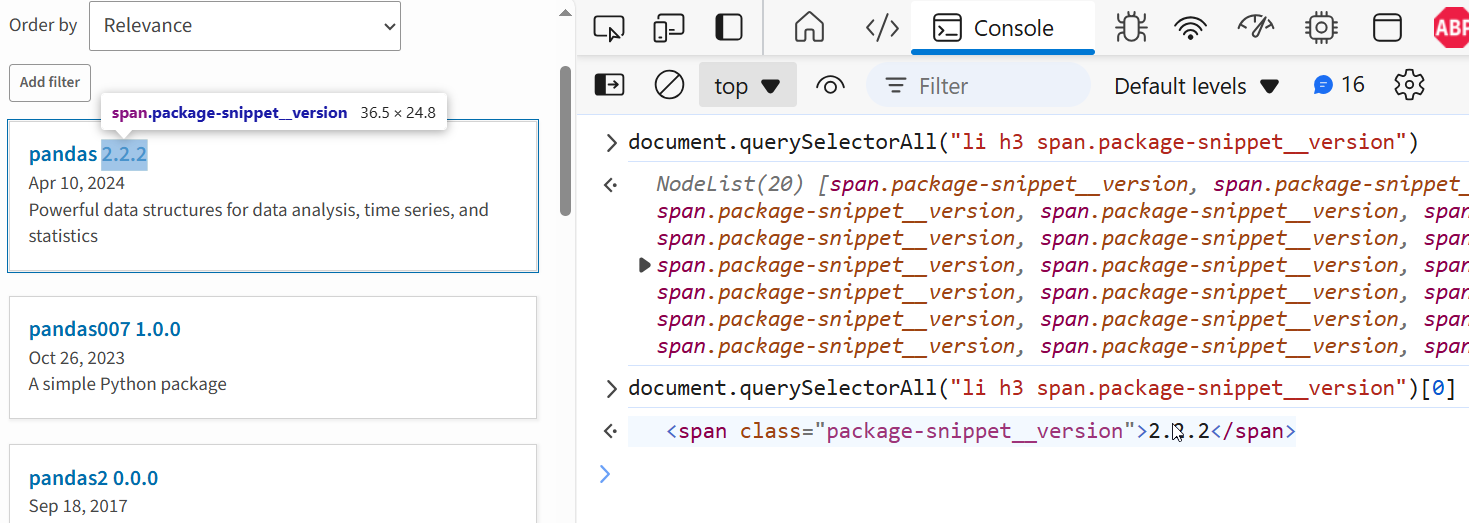
Figura 1. Ricerca di tutte le componenti contenenti i numeri di versione
Abbiamo provato delle query CSS per ottenere tutti i nodi di tipo span che contengono i numeri di versione ricavando uno dei possibili percorsi. Notare come l'oggetto NodeList ottenuto ci informi, con l'annotazione tra parentesi, che ci sono 20 elementi di quel tipo e di come la struttura dati sia facilmente navigabile per scoprire se siamo riusciti a realizzare il nostro intento. Da qui in poi possiamo copiare il selettore CSS ed usarlo in Selenium.
Verificare l'inserimento dei dati
L'utilizzo di Selenium non porta solo alla lettura di dati ma anche, molto spesso invero, al loro inserimento. In tali casi, è importante saper verificare che l'inserimento sia avvenuto con successo. Frequentemente, l'effetto da controllare è una corretta creazione di dati su database o una scrittura di file su disco. Per effettuare tale verifica dobbiamo decidere come muoverci soprattutto in relazione alla "visibilità" di cui disponiamo nel sistema.
Se, ad esempio, abbiamo esclusivamente accesso alle pagine web dovremo muoverci per forza tramite quelle. Nel caso in cui, supponiamo, abbiamo testato la creazione di post su un blog, per verificarne l'effettivo inserimento, dovremo richiamare l'elenco di contenuti pubblicati e verificarne la presenza oppure attendere l'apparizione di un qualche messaggio di conferma del salvataggio leggendo un alert, una frase stampata o un link.
Se invece abbiamo accesso al sistema su cui la macchina è in produzione potremmo fare dei test con verifica. Controllando che siano stati creati i corrispondenti record nel database o contenuti sul filesystem. Tali aspetti dovranno essere presi in considerazione prima della scrittura dei test.
Test unitari o di integrazione?
Ultimo punto su cui riflettiamo è la quantità di funzionalità che vogliamo testare. Senza addentrarci nella vastità dell'Ingegneria del Software, consideriamo che ogni test che immagineremo tenderà a verificare una singola funzionalità o un loro insieme.
Se, ad esempio, eseguiremo un test per valutare se una pagina web, dati due numeri, riesce a calcolare la loro divisione o sia in grado di restituire l'errore corretto se il divisore è uno zero staremo facendo un test unitario. Finalizzato a verificare un caso molto specifico. Se invece effettueremo un login in un CMS, per poi inserire un post e alla fine verificare che questo sia pubblicato in homepage, avremo verificato al contempo non una funzionalità bensì l'integrazione di più di esse, distribuite tra pagine web, database ed eventuali API e stored procedure.
I primi, i test unitari, sono fondamentali per essere sicuri che ogni singolo elemento sia in grado di funzionare e continui a farlo anche dopo ulteriori aggiornamenti apportati all'applicazione. Di questi ce ne serviranno molti ma anche i test di integrazione sono importanti in quanto non solo mettono alla prova singole attività ma permettono di sondare la capacità di risposta del sistema a procedimenti più lunghi e la fluidità della comunicazione tra le componenti.
Nel seguito della guida vedremo alcuni strumenti Python dedicati ai test e svolgeremo dei test più articolati, alcuni unitari altri di integrazione.

