
Riprendiamo il discorso su XPath e ricorriamo all'esempio in Bootstrap visto qualche lezione fa:
<div class="list-group col-md-6 col-md-offset-1" style="margin: auto">
<a href="#" class="list-group-item list-group-item-action flex-column align-items-start">
<div class="d-flex w-100 justify-content-between">
<h5 class="mb-1">Andrea Rossi campione italiano</h5>
<small>12/02/2024</small>
</div>
<p class="mb-1">Al termine di una prova estremamente estenuante Andrea Rossi si è di nuovo laureato campione italiano a Imola.</p>
<small class="text-muted">Autore: Simona Bianchi</small>
</a>
<a href="#" class="list-group-item list-group-item-action flex-column align-items-start">
<div class="d-flex w-100 justify-content-between">
<h5 class="mb-1">Lo Sporting ha il suo nuovo stadio</h5>
<small class="text-muted">11/02/2024</small>
</div>
<p class="mb-1">Finalmente, dopo quasi due anni di lavori, possiamo dire orgogliosamente che lo stadio dello Sporting è pronto a ricevere i suoi tifosi</p>
<small class="text-muted">Autore: Gianluca Neri</small>
</a>
<a href="#" class="list-group-item list-group-item-action flex-column align-items-start">
<div class="d-flex w-100 justify-content-between">
<h5 class="mb-1">Carlotta Gialli: nuovo record</h5>
<small class="text-muted">10/02/2024</small>
</div>
<p class="mb-1">Carlotta Gialli è riuscita nell'impresa di centrare il nuovo record italiano. Prossimo obiettivo? Superare quello europeo!</p>
<small class="text-muted">Autore: Simona Bianchi</small>
</a>
</div>che produce una visualizzazione di questo tipo:
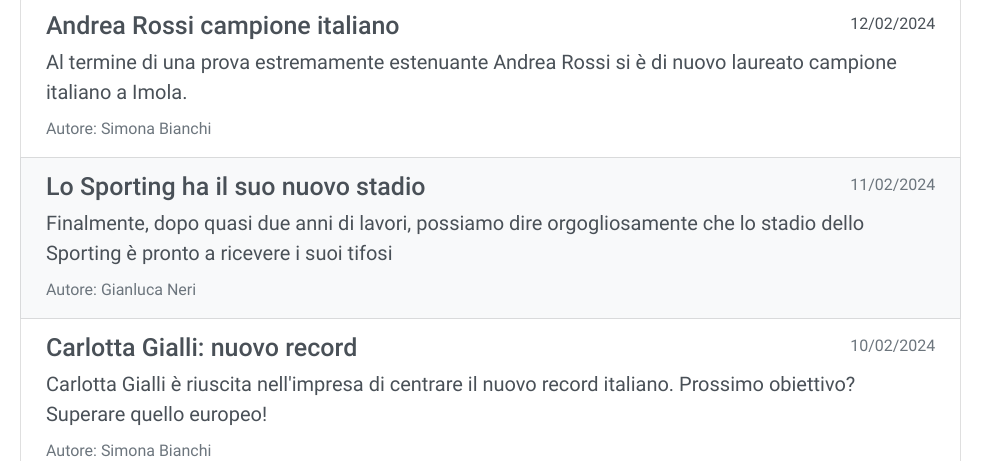
Figura 1. La struttura da analizzare
In tali casi, in cui gli elementi sono fortemente annidati tra loro, contraddistinti da svariate classi e definiti su tag molto variagati, XPath può essere molto utile muovendosi tra espressioni più generiche e accessi estremamente precisi. Notiamo che ogni singola notizia è racchiusa in un nodo HTML a. Il modo in cui abbiamo scelto di svolgere l'esercizio (ne esistono tanti altri alternativi che potranno costituire utilissimi esercizi) consiste nei seguenti passi:
- apriamo il driver e invochiamo la pagina web da analizzare, nel nostro caso si chiama
index_bs.htmled è contattabile su un server web in locale; - richiediamo i nodi delle notizie corrispondenti a nodi
acontenenti, tra le altre, la classelist-group-item; - con un ciclo creiamo tanti oggetti di classe
Notizia; - archiviamo ogni oggetto prodotto nella lista
notizie_del_giorno; - per verifica stampiamo in output gli oggetti prodotti.
Questo è il codice corrispondente ai quattro passaggi:
notizie_del_giorno=[]
driver.get("http://localhost/index_bs.html")
notizie = driver.find_elements(By.XPATH, "//*/a[contains(@class,'list-group-item')]")
for notizia in notizie:
notizie_del_giorno.append(Notizia(notizia))
for n in notizie_del_giorno:
print(n)Notiamo che ogni elemento a contiene molte classi e per richiederlo via XPath dovremmo indicare la sequenza completa. Per questo motivo, abbiamo usato l'utilissimo operatore contains che permette di riconoscere gli elementi in base ad una parte contenuta nell'attributo a cui facciamo riferimento.
La classe Notizia
La classe Notizia riceve come argomento del costruttore un singolo nodo WebElement recuperato da Selenium e lo partiziona in una serie di componenti interne dell'oggetto:
class Notizia:
def __init__(self, nodo):
self.titolo=nodo.find_element(By.TAG_NAME, "h5").text
self.descrizione=nodo.find_element(By.TAG_NAME, "p").text
self.data=nodo.find_element(By.XPATH, 'div/small').text
self.autore=nodo.find_element(By.XPATH, 'small').text.split(':')[1].strip()
def __str__(self):
return f'Titolo: {self.titolo}\nAutore: {self.autore}\nData: {self.data}\nDescrizione: {self.descrizione}\n'Un aspetto interessante è vedere come nel costruttore abbiamo scelto di estrapolare le varie porzioni di testo. A titolo di ripasso, abbiamo anche utilizzato un approccio per tag. Il titolo e la descrizione erano inseriti in tag unici, h5 e p, e per questo abbiamo preferito procedere interrogandoli senza XPath.
Con XPath invece abbiamo scelto di cercare un tag small dentro a un div ed uno non contenuto in niente. Tra l'altro, nell'ultima operazione siamo intervenuti sulla stringa per eliminare il prefisso "Autore: " che era presente prima del nome di chi aveva scritto l'articolo.
Stampa finale
Alla fine i risultati ottenuti, appaiono come segue:
Titolo: Andrea Rossi campione italiano
Autore: Simona Bianchi
Data: 12/02/2024
Descrizione: Al termine di una prova estremamente estenuante Andrea Rossi si è di nuovo laureato campione italiano a Imola.
Titolo: Lo Sporting ha il suo nuovo stadio
Autore: Gianluca Neri
Data: 11/02/2024
Descrizione: Finalmente, dopo quasi due anni di lavori, possiamo dire orgogliosamente che lo stadio dello Sporting è pronto a ricevere i suoi tifosi
Titolo: Carlotta Gialli: nuovo record
Autore: Simona Bianchi
Data: 10/02/2024
Descrizione: Carlotta Gialli è riuscita nell'impresa di centrare il nuovo record italiano. Prossimo obiettivo? Superare quello europeo!
