
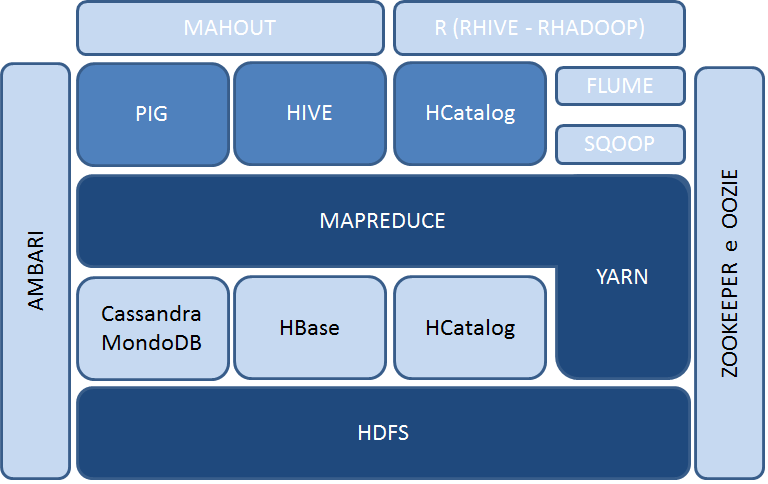
In questo capitolo descriveremo alcune componenti che costituiscono il nucleo centrale della piattaforma di calcolo distribuito; nello specifico verranno presentati:
| Componente | Descrizione |
|---|---|
| Hadoop common | Uno strato software comune che fornisce funzioni di supporto agli altri moduli. |
| HDFS | File system distribuito che fornisce un'efficace modalità di accesso ai dati. Garantisce che i dati siano ridondanti nel cluster rendendo le operazioni sui dati stessi immuni dall'eventuale guasto di un nodo. HDFS accetta dati in qualsiasi formato, strutturati e non strutturati. Di HDFS parleremo a breve in maniera dettagliata. |
| Map-Reduce | Un pattern che implementato permette di realizzare sistemi di computazione parallela e distribuita di grandi quantità di dati lavorando secondo il principio del "divide-et-impera". |
| YARN | Un framework che consente di creare applicazioni o infrastrutture per il calcolo distribuito (sulla base di MapReduce). Esso si occupa della gestione delle risorse del cluster (memoria/CPU/storage). |
Inoltre, si aggiungono al nucleo centrale una serie di altri sistemi software che completano quello che può essere definito "Ecosistema Hadoop".
HDFS: Architettura e funzionamento
Come anticipato, HDFS è un file system distribuito ideato per soddisfare requisiti quali affidabilità e scalabilità ed è in grado di gestire un numero elevatissimo di file, anche di dimensioni ragguardevoli (dell'ordine dei gigabyte o terabyte), attraverso la realizzazione di cluster che possono contenere migliaia di nodi.
HDFS presenta i file organizzati in una struttura gerarchica di cartelle. Dal punto di vista dell'architettura, un cluster è costituito dai seguenti tipi di nodi:
- NameNode: è l'applicazione che gira sul server principale. Gestisce il file system ed in particolare il namespace, cioè l'elenco dei nomi dei file e dei blocchi (i file infatti vengono divisi in blocchi da 64/128MB) e controlla l'accesso ai file, eseguendo le operazioni di apertura, chiusura e modifica dei nomi di file. Inoltre, determina come i blocchi dati siano distribuiti sui nodi del cluster e la strategia di replica che garantisce l'affidabilità del sistema. Il NameNode monitora anche che i singoli nodi siano in esecuzione senza problemi e in caso contrario decide come riallocare i blocchi. Il NameNode distribuisce le informazioni contenute nel namespace su due file: il primo è fsimage, che costituisce l'ultima immagine del namespace; il secondo è un log dei cambiamenti avvenuti al namespace a partire dall'ultima volta in cui il file
fsimageè stato aggiornato. Quando il NameNode parte effettua un merge difsimagecon il log dei cambiamenti così da produrre uno snapshot dell'ultima situazione. - DataNode: applicazione/i che girano su altri nodi del cluster, generalmente una per nodo, e gestiscono fisicamente lo storage di ciascun nodo. Queste applicazioni eseguono, logicamente, le operazioni di lettura e scrittura richieste dai client e gestiscono fisicamente la creazione, la cancellazione o la replica dei blocchi dati.
- SecondaryNameNode:noto anche come CheckPointNode, si tratta di un servizio che aiuta il NameNode ad essere più efficiente. Infatti si occupa di scaricare periodicamente il file
fsimagee i log dei cambiamenti dal NameNode, di unirli in un unico snapshot che è poi restituito al NameNode. - BackupNode: è il nodo di failover e consente di avere un nodo simile al SecondaryNameNode sempre sincronizzato con il NameNode.
Come abbiamo affermato in precedenza, i file sono organizzati in blocchi da 64 o 128MB e sono ridondati su più nodi. Sia la dimensione dei blocchi, sia il numero di repliche possono essere configurate per ogni file. Le repliche sono utilizzate sia per garantire l'accesso a tutti i dati (anche in presenza di problemi a uno o più nodi) sia per rendere più efficiente il recupero dei dati.
In HDFS le richieste di lettura dati seguono una politica relativamente semplice: avvengono scegliendo i nodi più vicini al client che effettua la lettura e, ovviamente, in presenza di dati ridondati risulta più semplice soddisfare questo requisito. Inoltre, occorre precisare che la creazione di un file non avviene direttamente attraverso il NameNode. Infatti, il client HDFS crea un file temporaneo in locale e solo quando tale file supera la dimensione di un blocco, è preso in carico dal NameNode.
Quest'ultimo crea il file all'interno della gerarchia del file system, identifica un DataNode e i blocchi su cui posizionare i dati. Successivamente DataNode e blocchi sono comunicati al client HDFS che provvede a copiare i dati dalla cache locale alla sua destinazione finale.
Archivi Hadoop
Quanto detto fino ad ora, ci permette di concludere che quando vengono trattati files di grandi dimensioni, HDFS è molto efficiente. Ma cosa succede quando tratta con file di piccole dimensioni, dove per piccole dimensioni si intendono dimensioni inferiori al blocco? In questo caso è molto inefficiente, questo perché i file utilizzano spazio all'interno del namespace, cioè l'elenco dei file mantenuti dal NameNode, che ha un limite dato dalla memoria del server che ospita il NameNode stesso.
Se HDFS contenesse troppi file associati ad una dimensione molto inferiore al singolo blocco, genererebbe un riempimento del namespace. Questo problema viene risolto dagli archivi Hadoop che compattano molti piccoli file in file più grandi ai quali è possibile accedere dal sistema in parallelo e senza necessità di espanderli.
Gli archivi hadoop hanno estensione .har e sono creati attraverso un comando che verrà descritto in seguito, inoltre hanno un formato particolare, suddiviso in tre componenti.
- un
master indexche contiene il posizionamento dei file originali dell'archivio; - un
indexche contiene lo stato dei file; - le parti, che contengono i dati.
Quanto descritto fino a questo momento, e in particolare i riferimenti al funzionamento di HDFS, consentirà di passare all'analisi delle metodologie d'utilizzo del file system che verranno affrontate nel prossimo capitolo.

