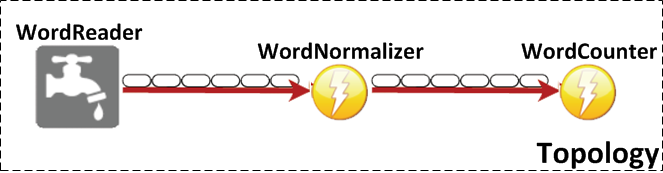
L'esempio che utilizzeremo per affrontare questa parte pratica della guida consiste nella seguente traccia: lettura di un file contenente un insieme di parole (una su ogni riga), normalizzazione delle parole lette e conteggio delle occorrenze, queste ultime due operazioni eseguite a cascata. Prima di addentrarci nel codice, progettiamo quello che sarà il TOPOLOGY risultante e che andremo ad implementare.
Nell'esempio proposto, lo stream in ingresso è costituito da un file txt da leggere; dunque, implementiamo uno SPOUT che legge un file di testo ed inoltra il contenuto letto ai BOLTS che effettueranno le due operazioni descritte: normalizzazione delle parole e conteggio delle occorrenze. Quindi suggeriamo di implementare due BOLTS, ognuno predisposto ad effettuare una delle elaborazione descritte. Di seguito il risultato di questa breve fase di progettazione:
Creazione del progetto in Eclipse
Siamo pronti per implementare la nostra soluzione utilizzando il framework Storm. Per lo sviluppo del codice è stato utilizzato Eclipse Java EE Juno. Per gestire un progetto di questo tipo, utilizzeremo il tool Maven. Dopo aver creato il progetto in Eclipse, ci troveremo
di fronte un risultato simile a quello della figura sottostante, ben noto a chi utilizza il tool Maven.

Grazie all'utilizzo del tool Maven, possiamo facilmente aggiungere la dipendenza del framework Storm, configurando opportunamente il file pom.xml; in particolare, ci assicureremo di impostare repository e dipendenza Storm come segue:
clojars.org
http://clojars.org/repo
storm
storm
0.8.1
providedUna volta configurato il file pom.xml, possiamo utilizzare il framework. Prima di tutto, creiamo 3 diversi package nella directory src/main/java:
| Package | Descrizione |
|---|---|
| spount | Conterrà le classi che implementano gli SPOUTS. |
| BOLTS | Conterrà le classi che implementano i BOLTS. |
| topologies | Conterrà le classi che implementano i topologies. |
L'albero progetto risultante dalla creazione dei 3 packege descritti sarà il seguente: