
TOPOLOGY
Come gia anticipato, un TOPOLOGY è l'insieme di componenti SPOUTS e BOLTS e delle loro connessioni. In questo paragrafo vedremo più in dettaglio come avviene lo scambio di tuple tra i vari componenti di un TOPOLOGY e quali tecniche si possono adoperare per progettare un
TOPOLOGY in maniera efficiente ed efficace. Una caratteristica fondamentale da considerare quando si progetta un TOPOLOGY, è definire come i dati sono scambiati tra i vari componenti, cioè come gli stream vengono consumati dai BOLTS.
A tal proposito si definisce uno Stream Grouping, una tecnica che specifica quali streams sono consumati da ogni BOLT e come lo stream verrà consumato. Un nodo, infatti, può emettere più di uno stream di dati. Una tecnica di Stream Grouping, permette di scegliere quali stream ricevere. Esistono diversi tipi di Stream Grouping:
| Stream Grouping | Descrizione |
|---|---|
| Shuffle Grouping | Ogni tupla emessa viene inviata ad un BOLT scelto a caso, garantendo però che ogni consumatore riceverà lo stesso numero di tuple. |
| Fields Grouping | Permette di controllare in che modo le tuple sono inviate ai BOLTS, basandosi su uno o più campi della tupla stessa. Garantisce che un dato set di valori per una certa combinazione di campi, sia sempre inviata allo stesso BOLT. |
| All Grouping | Una singola copia di ogni tupla viene inviata a tutte le istanze dei BOLTS. Generalmente, questo tipo di grouping è usato per inviare segnali ai BOLTS. Ad esempio, se è necessario effettuare un refresh di una cache, è possibile inviare un refresh cache signal a tutti i BOLTS. In tale contesto, potrebbe essere necessario identificare i segnali e da quali sorgenti provengono: in questo caso Storm permette di identificare gli streams associandogli un nome. |
| Custom Grouping | Attraverso l'implementazione dell'interfaccia CustomStreamGrouping, è possibile implementare una tecnica di grouping personalizzata. Ciò fornisce il potere di decidere quali BOLTS riceveranno ogni tupla. |
| Direct Grouping | Con questo grouping, è la sorgente che decide quale componente riceverà la tupla. |
| Global Grouping | Permette di inviare le tuple generate da tutte le istanze di una sorgente ad una singola istanza target. |
SPOUT
Gli SPOUTS, si limitano a prelevare un flusso da una certa sorgente e ad inoltrarlo ai BOLTS. Dunque è possibile fare riferimento a diverse architetture per decidere il modo più efficace ed efficiente per prelevare i flussi dalla sorgente.
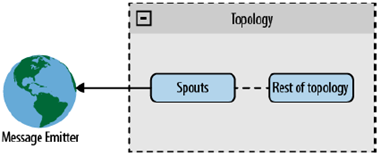
- Direct Connection: uno SPOUT è direttamente connesso alla sorgente che emette un flusso. L'architettura è semplice da implementare e adatta quando la sorgente è nota e rimane costante. Viene considerata sorgente non nota se questa viene aggiunta dopo che un TOPOLOGY è stato già messo in esecuzione;
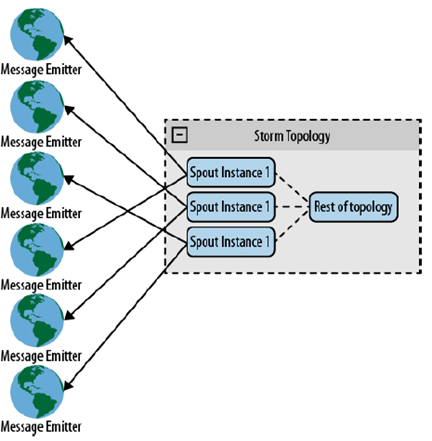
- Direct Connection Hashing: questo tipo di architettura, è adatto quando esistono diverse sorgenti eterogenee che emettono flussi e si vuole parallelizzare l'elaborazione tra più SPOUTS. In un contesto del genere, Storm offre una feature interessante: permette l'accesso al contesto del TOPOLOGY da qualsiasi componente (SPOUT/BOLT). Utilizzando questa feature, è
possibile suddividere i diversi streams tra più istanze di SPOUT;
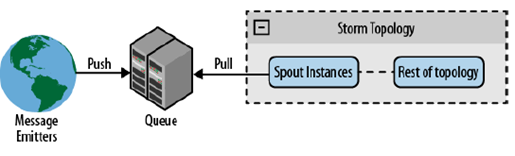
- Enqueued Messages: un approccio differente dai precedenti, consiste nel collegare un SPOUT ad un sistema che mantiene una coda dei flussi emessi dalle sorgenti. Tale approccio, svincola la progettazione dalla conoscenza delle sorgenti in quanto il sistema intermedio può fungere da middlware. Allo stesso tempo il sistema intermedio può essere un collo di bottiglia dell'intero sistema.
BOLT
BOLT è un componente che prende le tuple in input, le elabora e produce delle tuple in output. I BOLT sono creati su una macchina client, serializzati in un TOPOLOGY e inviati ad un nodo master del cluster. Il cluster lancia i nodi workers che deserializzano il BOLT e successivamente inizia l'elaborazione delle tuple.

