Per prima cosa creiamo un nuovo "load balancer" tramite l'interfaccia web di AWS, quindi nella gestione delle EC2 facciamo click sul menu dedicato ai bilanciatori di carico e poi facciamo click su "Create Load Balancer".

Non dobbiamo fare altro che assegnare un nome al nostro load balancer, in questo esempio "WPAppLoadBalancer", e configurare il "routing" delle porte, per i nostri scopi è sufficiente far puntare la porta 80 del load balancer con la porta 80 delle istanze poste dietro di lui. Ora proseguiamo per la configurazione del "sanity check".
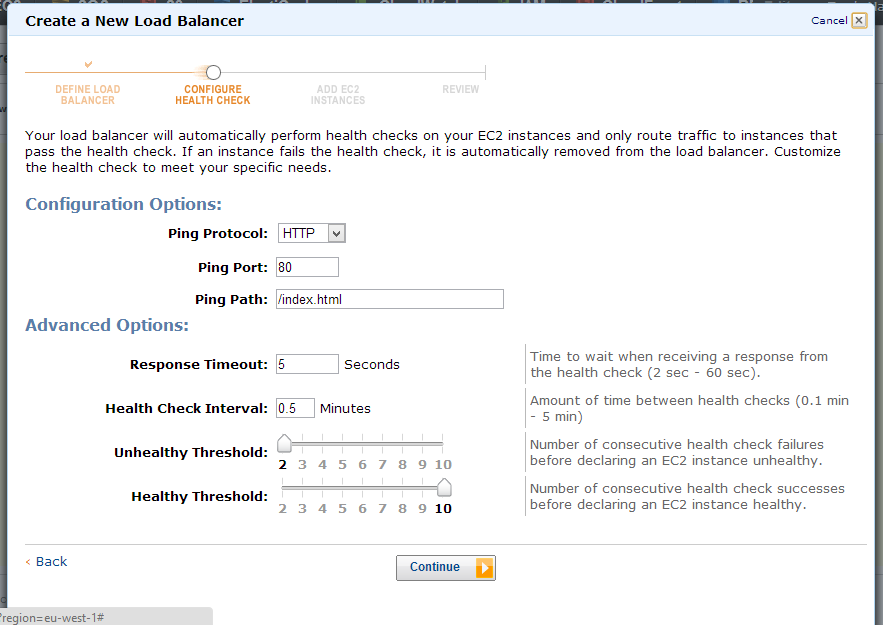
Il "sanity check" è la procedura con cui il nostro load balancer controlla le singole istanze per stabilire se incorrono del problemi oppure sono al 100% operative, reagendo di conseguenza ad ogni problema insorto.
Il meccanismo di default si basa su un controllo a livello di HTTP, ovvero a intervalli regonari di qualche secondo viene richiesta una pagina (la root "/") e viene controllato l'header di risposta: se si riceve un codice di errore per più di un certo numero di secondi, l'istanza viene marcata come "non coerente" e rimossa dal load balancer. Il sistema di autoscaling si occuperà di sostituire l'istanza se lo stato del sistema lo richiede così da riportarlo in stabilità.
Proseguendo al terzo step si vanno ad aggiungere le macchine virtuali per la base del sistema.
Per i nostri scopi di autoscaling possiamo proseguire senza aggiungere nessuna macchina virtuale, in quanto il sistema di autoscaling si occuperà di configurare il sistema con il template e lo "script di boot".
Si può configurare l'autoscaling e si possono utilizzare tutte le SDK disponibili direttamente su aws.amazon.com ma per semplicità utilizzeremo le CLI (Command Line Interface) ovvero tool tipicamente scritti in ruby, disponibili sempre sul sito di Amazon. In particolare abbiamo bisogno di due componenti: AutoScaling e CloudWatch.
Per attivare i servizi di autoscaling dobbiamo in primo luogo creare una configurazione di autoscaling, successivamente un gruppo di autoscaling, creare una soglia di attivazione tramite CloudWatch e per concludere legare una policy di autoscaling.
Inziamo creando la configurazione:
as-create-launch-config MyLC --image-id ami-xxxxxxxx --instance-type m1.small --region eu-west-1 --key my-keys.pem --group "my-group-name" --user-data-file /home/walter/git/config/my-ec2-init-scriptQuesto primo comando crea solo una configurazione chiamata "MyLC" su cui viene impostato l'identificativo dell'AMI che abbiamo creato (visibile tramite console web), il tipo dell'istanza "m1.small", la regione in cui si lavora "eu-west-1", il gruppo di chiavi da utilizzare "my-keys.pem", il security group "my-group-name" e per finire lo script di shell che deve essere eseguito durante il boot della macchina virtuale. "my-ec2-init-script".
Ora possiamo creare il gruppo per lo scaling tramite il comando:
as-create-auto-scaling-group MyASG --launch-configuration MyLC --availability-zones eu-west-1a eu-west-1b --min-size 1 --max-size 5 --load-balancers frontinstance-balancer --region eu-west-1A questo comando passiamo la configurazione che deve essere utilizzata, le zone di disponibilità, facendo attenzione che corrispondano a quelle del load balancer, il numero minimo di server che devono essere disponibili, il numero massimo di questi, il load balancer su cui registrare le istanze e la regione di lavoro.
I parametri di dimensione di autoscaling sono molto importanti: successivamente a questo comando si entra subito in una condizione di scalata in quanto il numero minimo di istanze è 1, quindi deve essere resa disponibile la prima istanza. Se controlliamo la console vedremo che una nuova VM sta facendo il boot o è disponibile.
Il numero massimo di istanze attive è 5 da questa configurazione, con l'evidente significato di limitazione sul numero di server che devono essere presenti nel gruppo.
Ora configuriamo gli allarmi per far scalare in fuori il nostro sistema quando il carico sulle CPU supera un certo limite. Per fare questo in primo luogo dobbiamo registrare un allarme su CloudWatch, e poi imporre al sistema di autoscaling di ascoltare questo segnale così da "allargare" la capacità di calcolo a comando.
as-put-scaling-policy MyScaleUp --auto-scaling-group MyASG --adjustment=1 --type ChangeInCapacity --cooldown 300 --region eu-west-1La policy di autoscaling, con nome "MyScaleUp" sul gruppo "MyASG", definito precedentemente, deve "aggiustare" di una macchina virtuale la dimensione del gruppo, ovvero ne deve aggiungere una. Prima di passare oltre, vi sarete accorti che questo comando risponde con una stringa molto lunga che è necessaria per legarla alle metriche di CloudWatch, come in questo esempio:
arn:aws:autoscaling:eu-west-1:123456888888:scalingPolicy:33333333-3333-33333-1111-11111111111:autoScalingGroupName/MyASG:policyName/MyScaleUpNon ci resta che legare questa policy ad un allarme dedicato:
mon-put-metric-alarm MyHighCPUAlarm --comparison-operator GreaterThanThreshold --evaluation-periods 1 --metric-name CPUUtilization --namespace "AWS/EC2" --period 300 --statistic Average --threshold 75 --alarm-actions arn:aws:autoscaling:eu-west-1:123456888888:scalingPolicy:333333-3333-33333-1111-11111111111:autoScalingGroupName/MyASG:policyName/MyScaleUp --dimensions "AutoScalingGroupName=MyASG"Il comando crea un allarme di nome "MyHighCPUAlarm" che si basa sulla comparazione di una soglia ogni minuto della metrica di media di utilizzo di CPU per 5 minuti, se questa supera la soglia del 75% in tutti i campioni allora è utilizzata la policy di autoscaling, ovvero il gruppo cresce di una unità come specificato nella policy. Stesso discorso, ma invertito, si fa per ridurre il numero di istanze attive tramite una policy di "discesa" ed un'allarme dedicato:
as-put-scaling-policy MyScaleDown --auto-scaling-group MyASG --adjustment=-1 --type ChangeInCapacity --cooldown 300 --region eu-west-1
mon-put-metric-alarm MyDownCPUAlarm --comparison-operator LessThanThreshold --evaluation-periods 1 --metric-name CPUUtilization --namespace "AWS/EC2" --period 300 --statistic Average --threshold 20 --alarm-actions arn:aws:autoscaling:eu-west-1:123456888888:scalingPolicy:22222222-2222-2222-222-22222222222:autoScalingGroupName/MyASG:policyName/MyScaleDown --dimensions "AutoScalingGroupName=MyASG"Come si può vedere un questo esempio il gruppo scende un una unità e le metriche sono attivate quando il consumo scende sotto la soglia del 20% di CPU.
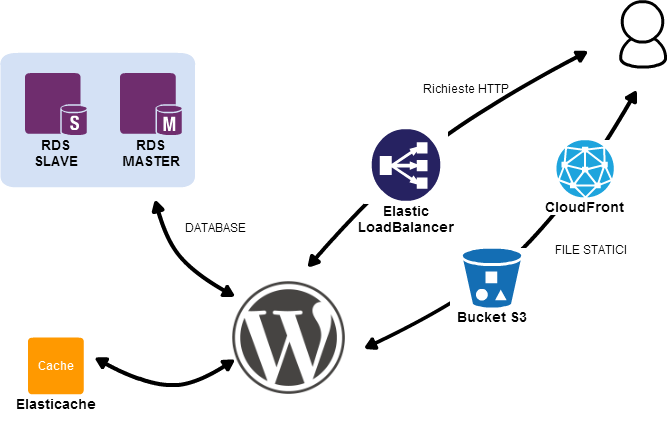
Ecco come si presenta ora la nostra infrastruttura.