
Andiamo ora ad introdurre una tipologia di reti neurali, denominata Autoencoder, utilizzate per ottenere una rappresentazione compressa dei dati in input.
Architettura
L'architettura di un Autoencoder prevede due componenti: encoder e decoder. Il primo riceve i dati in input e ne fornisce una rappresentazione
compressa o latent space representation. Il decoder riceve in input la versione compressa del dato e lo riproduce con il minor errore possibile.
Un Autoencoder è caratterizzato da:
- specificità del dato, se lo addestriamo nella riproduzione di immagini di persone non possiamo impiegarlo per riprodurre immagini di animali;
- un output non è esattamente uguale all'input, quindi se desideriamo una riproduzione fedele l'Autoencoder non è la soluzione ottimale;
- apprendimento non supervisionato, abbiamo bisogno dei soli dati senza etichette di classificazione.

Nell'immagine che segue mostriamo una rappresentazione dettagliata di un Autoencoder. L'input viene ricevuto da una rete neurale (encoder) costituita da un input layer (i dati in input), un hidden layer, e un output layer. L'output layer produce la rappresentazione compressa del dato. L'output layer dell'encoder diventa l'input layer della seconda rete neurale costituita dal decoder.
Il decoder continua con un hidden layer e un output layer per la riproduzione del dato in input dell'encoder.
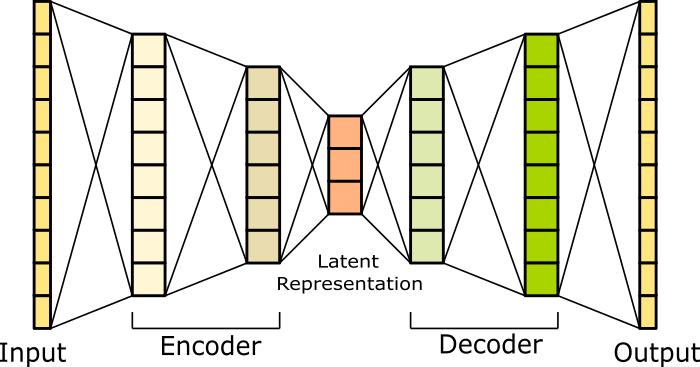
Implementazione
Realizziamo un Autoencoder con un hidden layer sia per l'encoder che per il decoder. L'Autoencoder deve apprendere una rappresentazione compressa delle cifre comprese tra 0 e 9
utilizzando il dataset MNIST. A tal fine definiamo una classe scheletro in cui aggiungere progressivamente l'implementazione:
import org.deeplearning4j.datasets.iterator.impl.MnistDataSetIterator;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.SplitTestAndTrain;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.learning.config.Adam;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import java.util.*;
import java.util.List;
public class Autoencoder {
public static void main(String[] args) throws Exception {}
}Dobbiamo prima di tutto costruire il nostro Autoencoder tramite la classe MultiLayerConfiguration
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(12345)
.weightInit(WeightInit.XAVIER)
.updater(new Adam(0.001))
.activation(Activation.RELU)
.l2(0.0001)
.list()
.layer(new DenseLayer.Builder().nIn(784).nOut(250)
.build())
.layer(new DenseLayer.Builder().nIn(250).nOut(10)
.build())
.layer(new DenseLayer.Builder().nIn(10).nOut(250)
.build())
.layer(new OutputLayer.Builder().nIn(250).nOut(784)
.activation(Activation.LEAKYRELU)
.lossFunction(LossFunctions.LossFunction.MSE)
.build())
.build();
MultiLayerNetwork net = new MultiLayerNetwork(conf);
net.setListeners(Collections.singletonList(new ScoreIterationListener(10)));Il codice presentato evidenzia l'uso di un ottimizzatore tipo Adam e un loss function di tipo MSE. In particolare la loss function sarà la somma delle differenze dei valori RGB tra l'immagine in output e quella in input. Attraverso l'algoritmo di backpropagation cercheremo di ottenere un modello che minimizza questo errore e che abbia un buon livello di generalizzazione.
Proseguiamo con il recupero del dataset suddividendolo in un blocco per l'addestramento e uno per il testing:
DataSetIterator iterator = new MnistDataSetIterator(100,50000,false);
List<INDArray> train = new ArrayList<>();
List<INDArray> test = new ArrayList<>();
List<INDArray> labels = new ArrayList<>();
while(iterator.hasNext()){
DataSet ds = iterator.next();
SplitTestAndTrain testAndTrain = ds.splitTestAndTrain(80, new Random(12345));
train.add(testAndTrain.getTrain().getFeatures());
DataSet dsTest = testAndTrain.getTest();
test.add(dsTest.getFeatures());
INDArray indexes = Nd4j.argMax(dsTest.getLabels(),1); // one-hot representation -> index
labels.add(indexes);
}Le immagini del dataset sono da 28x28 px presentate come vettori di dimensione 784 = 28*28. Le label per le cifre 0-9 sono codificate nella modalità one-hot encoding. In questa codifica le label sono rappresentate con un vettore la cui dimensione è pari al numero possibile di cifre. Il vettore avrà tutti elementi nulli tranne quello la cui posizione identifica
una particolare cifra.
Se ad esempio volessimo rappresentare l'1 la corrispondente codifica sarebbe:

Addestriamo la nostra rete per un numero di epoche che riteniamo sufficienti:
int nEpochs = 5;
for( int epoch=0; epoch<nEpochs; epoch++ ){
for(INDArray data : train){
net.fit(data,data);
}
System.out.println("Epoch " + epoch + " complete");
}Stampiamo infine alcuni risultati di test:
for( int i=0; i<test.size(); i++ ){
INDArray testData = test.get(i);
INDArray lbl = labels.get(i);
int nRows = testData.rows();
for( int j=0; j<nRows; j++){
INDArray example = testData.getRow(j, true);
int digit = (int)lbl.getDouble(j);
double score = net.score(new DataSet(example,example));
System.out.println("Label:"+digit);
System.out.println("Score:"+score);
}
}
