
Nella lezione precedente abbiamo visto che la definizione di classi contenitore ha tra i suoi requisiti fondamentali il concetto di iteratore.
Un iteratore in C++ è un entità preposta alla scansione di un contenitore secondo le sue modalità di accesso agli elementi, rispettandone vincoli quali la dimensione.
Gli iteratori possono essere considerati una specie primigenia di puntatori intelligenti o smart pointer, che risolve il problema della navigazione di classi contenitore eterogenee mediante il ricorso ad un'astrazione semplice ma consistente.
Perché si usano gli iteratori
Nel tipico caso d'uso di una struttura contenitore, il programmatore ha l'esigenza di codificare le istruzioni che consentono di scandire la struttura (interamente o in parte) e di effettuare delle elaborazioni a partire dai singoli elementi.
In quest'ottica, l'uso degli iteratori consente di rendere la programmazione meno dipendente dal tipo di struttura contenitore in uso. Questo perché esso consente di ridurre al minimo i requisiti che una classe contenitore deve soddisfare al fine di perpetrare un ciclo in maniera efficiente e generica.
Come esempio pratico si consideri il caso della scansione di un array in stile C mediante un semplice ciclo for.
// iterazione basata su indici per un array in stile C
int a[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
for (int i=0; i<10; i++)
{
std::cout << a[i] << ' ';
}Adattare questa porzione di codice alle strutture contenitore std::array o std::vector è immediato, e porta con sé il beneficio di poter desumere la dimensione direttamente al contenitore, anziché memorizzare questa informazione in una variabile o un letterale:
// iterazione basata su indici per un container std::vector
std::vector<int> v = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
for (int i=0; i<v.size(); i++)
{
std::cout << v[i] << ' ';
}Tuttavia, se avessimo l'esigenza di adattare questo codice all'uso di std::list sarebbero richieste modifiche più sostanziali. Innanzitutto, la lista non supporta l'operatore [] per l'accesso casuale ai suoi elementi. In secondo luogo il metodo size() della classe std::list effettua una scansione lineare dell'intero container. Esso è quindi molto più oneroso rispetto l'omonimo metodo size() della classe std::vector, il cui costo computazionale è costante e invariante rispetto alla dimensione del vettore.
In questo caso, quindi, l'uso di una struttura contenitore al posto di un'altra condizionerebbe fortemente sia la codifica che le prestazioni del programma.
L'uso degli iteratori si presta a risolvere proprio situazioni di questo tipo.
Il frammento di codice seguente contiene la trasposizione del ciclo precedente con l'uso di iteratori per la classe std::vector:
// iterazione basata su iteratori per std::vector
std::vector<int> v = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
for (std::vector<int>::iterator it = v.begin(); it != v.end(); ++it)
{
std::cout << *it << ' ';
}Si osservi che in questo caso la variabile del ciclo è un iteratore inizializzato alla prima posizione del container tramite il valore restituito dal metodo begin. La condizione d'uscita è basata sul confronto tra l'iteratore alla posizione corrente e quello che corrisponde alla posizione che delimita la fine del container restituito dal metodo end, senza fare riferimento al numero totale di elementi. Inoltre, l'iteratore supporta l'operazione di incremento '++' per predisporre la prossima iterazione, e di dereferenziazione '*' per consentire l'accesso all'elemento cui è associato.
Data la grande omogeneità della API delle classi container della STL, questa seconda versione del ciclo iterativo si presta ad una trasposizione immediata nel caso di liste o di altri tipi di container, garantendo prestazioni ottimali per il contenitore in uso:
// iterazione basata su iteratori per std::list
std::list<int> l = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
for (std::list<int>::iterator it = l.begin(); it != l.end(); ++it)
{
std::cout << *it << ' ';
}Si osservi che il tipo dell'iteratore dipende dal container di riferimento, in qualità di classe annidata di nome iterator. La regola generale per ricavare il tipo corretto è la seguente: nome_container<tipo_elemento>::iterator.
Tipi di iteratore
Le varie tipologie di classi contenitore sono specificamente progettato per ottimizzare le operazioni di accesso, inserimento o di ricerca, a seconda dei casi d'uso. Come conseguenza di ciò esistono diversi tipi di iteratori, specializzati per soddisfare i requisiti di ogni classe.
Nella Standard Template Library, le funzionalità dei vari iteratori sono strutturate in una gerarchia di classi. Ai vertici della gerarchia si trovano le classi che modellano comportamenti di base, mentre ai livelli successivi sono implementati comportamenti via via più complessi.
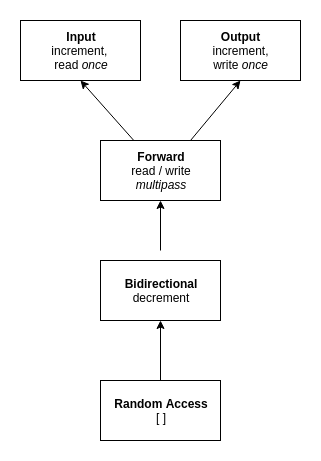
Nella gerarchia compaiono le seguenti entità:
- Input: iteratori di input per algoritmi singlepass
- Output: iteratori di output per algoritmi singlepass
- Forward: iteratori I/O per algoritmi multipass
- Bidirectional: iteratori I/O bidirezionali per algoritmi multipass
- Random access: iteratori I/O ad accesso casuale per algoritmi multipass
Gli iteratori di input e output costituiscono le basi della gerarchia, fornendo rispettivamente le funzionalità per l'accesso in lettura e scrittura dell'oggetto puntato dall'iteratore. Entrambe supportano l'operatore di incremento ++, che consente di spostarsi all'elemento successivo.
Tuttavia, a questo livello della gerarchia non si fanno assunzioni sul tipo di storage che il contenitore supporta. Pertanto la risorsa puntata da un iteratore di input o output potrebbe non essere più disponibile in seguito ad un'operazione di incremento. Come esempio, si consideri il caso di iteratori che operano su flussi o stream. Una volta estratto o inserito un elemento dal flusso, potrebbe non essere più possibile accedervi nuovamente.
Per questo motivo, questi iteratori possono essere usati solo con algoritmi singlepass, cioè algoritmi che non richiedono scansioni multiple dello stesso elemento.
Al livello successivo della gerarchia si trova la classe degli iteratori forward, che oltre a fondere in un'unica entità le funzionalità di lettura e scrittura, si basa sull'assunto che lo storage del container sia persistente rispetto l'operazione di incremento, come quando ad esempio, ci si sposta all'elemento successivo di una lista senza che ciò comporti l'alterazione di un riferimento all'elemento precedente, in quanto esso non cessa di esistere. Questo tipo di iteratori si presta dunque all'uso in algoritmi multipass, ad esempio quelli di ordinamento.
La classe di iteratori bidirezionali aggiunge il supporto alla operazione di decremento, consentendo di spostarsi anche indietro.
Infine, la classe di iteratori ad accesso casuale astrae la funzionalità di accesso ad ogni elemento di un container in tempo costante, come ad esempio avviene con la classe std::vector.
I vari tipi di iteratore della STL derivano dagli elementi di questa gerarchia, combinando le funzionalità specifiche per ogni classe contenitore.
Funzioni di utilità e limitazioni
Nella libreria STL esistono molteplici API che consentono di manipolare gli iteratori. Alcune sono esposte come metodi pubblici di classi contenitore, altre sono funzioni definite nel namespace std che forniscono varie funzionalità.
Iteratori const e invertiti
Come mostrato in precedenza, i metodi begin ed end consentono di inizializzare un iteratore facendolo puntare rispettivamente al primo elemento di un contenitore e alla posizione successiva all'ultimo elemento nota come past-the-last element.
Esistono delle varianti che consentono di ottenere iteratori const oppure iteratori di inizio e fine invertiti (reverse).
Nel primo caso si tratta dei metodi cbegin ed cend, usati per garantire che gli elementi puntati non devono essere modificati. Ogni tentativo di assegnare un valore all'elemento puntato da un iteratore const verrà segnalato come errore a tempo di compilazione.
Nel secondo caso, l'uso dei metodi rbegin ed rend consente di ottenere dei riferimenti di inizio e fine invertiti. Poiché anche le operazioni di incremento e decremento sono invertite, ciò può essere utile per alterare la modalità di scansione di un intervallo senza modificare la logica di un ciclo.
Il listato seguente mostra un esempio del loro utilizzo:
#include <iostream>
#include <vector>
int main()
{
std::vector<int> v {1, 2, 3, 4, 5, 6};
// uso di iteratori costanti
for (std::vector<int>::const_iterator it = v.cbegin(); it < v.cend(); it++)
{
std::cout << *it << ' ';
//*it = 2; // errore: gli elementi non possono essere modificati!
}
std::cout << "\n";
// uso di iteratori invertiti: stampa "6 5 4 3 2 1"
for (std::vector<int>::reverse_iterator it = v.rbegin(); it < v.rend(); it++)
{
std::cout << *it << ' ';
}
std::cout << "\n";
return 0;
}Si noti che il tipo restituito da queste varianti dei metodi begin ed end è rispettivamente nome_container<tipo_elemento>::const_iterator e nome_container<tipo_elemento>::reverse_iterator, che forniscono sovraccarichi degli operatori di incremento, decremento e dereferenziazione implementati in modo differente.
Spostamento
A parte gli operatori di incremento e decremento, la funzione advance consente di spostare un iteratore del numero desiderato di posizioni con un'unica istruzione. A partire dallo standard c++11 è inoltre possibile usare le funzioni next e prev in alternativa.
std::advance(it, 2); // incremento di due posizioni
std::advance(it, -2); // decremento di due posizioni
// oppure da C++11 in poi in modo equivalente
std::next(it, 2);
std::prev(it, 2);Ovviamente, per tutte le operazioni di spostamento resta la necessità di controllare che la posizione dell'iteratore sia valida, cioè punti ad un elemento compreso tra i valori restituiti da begin ed end.
Uso di iteratori su container ordinati
Occorre usare cautela quando si iteratori su container che definiscono implicitamente un ordinamento per i propri elementi come, ad esempio, std::map e std::set.
In questi casi infatti, modificare un elemento del contenitore in modo improprio potrebbe avere affetti distruttivi sull'ordinamento. In particolare, nel caso di std::map, in cui gli elementi sono costituiti da coppie chiave-valore, non è opportuno modificare la chiave di un elemento mediante dereferenziazione di un iteratore. È invece perfettamente lecito modificare il valore associato, poichè esso non contribuisce al modo in cui il contenitore gestisce il posizionamento dei suoi elementi.
Analogamente, modificare il valore di un elemento contenuto in un'istanza di tipo std::set mediante dereferenziazione di un iteratore potrebbe risultare rischioso, se ciò alterasse l'ordine predefinito dal contenitore.
Se vuoi aggiornamenti su Development inserisci la tua email nel box qui sotto:
