
Sara' ora presentata la struttura del database che verra' utilizzato
per gli esempi delle successive lezioni. Non verranno descritte le fasi
di analisi e i modelli concettuali e logici che sono stati necessari per
giungere a tale struttura, dal momento che cio' andrebbe al di fuori
degli scopi di questo corso. La struttura del database e' quella
rappresentata nel diagramma relazionale di Figura 3. Ogni rettangolo
rappresenta una relazione. Il nome della relazione e' contenuto nella
sezione piu' scura nella parte alta del rettangolo. Il resto del
rettangolo e' suddiviso in tre colonne, nelle quali sono definite le
caratteristiche degli attributi che compongono la relazione. La colonna
centrale contiene i nomi degli attributi, quella di destra il loro tipo
(sono stati utilizzati i tipi dell'SQL/92) e quella di sinistra le loro
proprieta'. Le proprieta' degli attributi sono indicate con le sigle
"PK" e "FK", le quali significano rispettivamente che i corrispondenti
attributi fanno parte della chiave primaria della relazione (Primary
Key) o di una chiave esterna (Foreign Key). Le frecce congiungono
appunto le chiavi esterne con le chiavi primarie a cui si riferiscono. I
nomi degli attributi in neretto indicano che tali attributi non possono
assumere il valore NULL, cioe' non possono essere indeterminati.
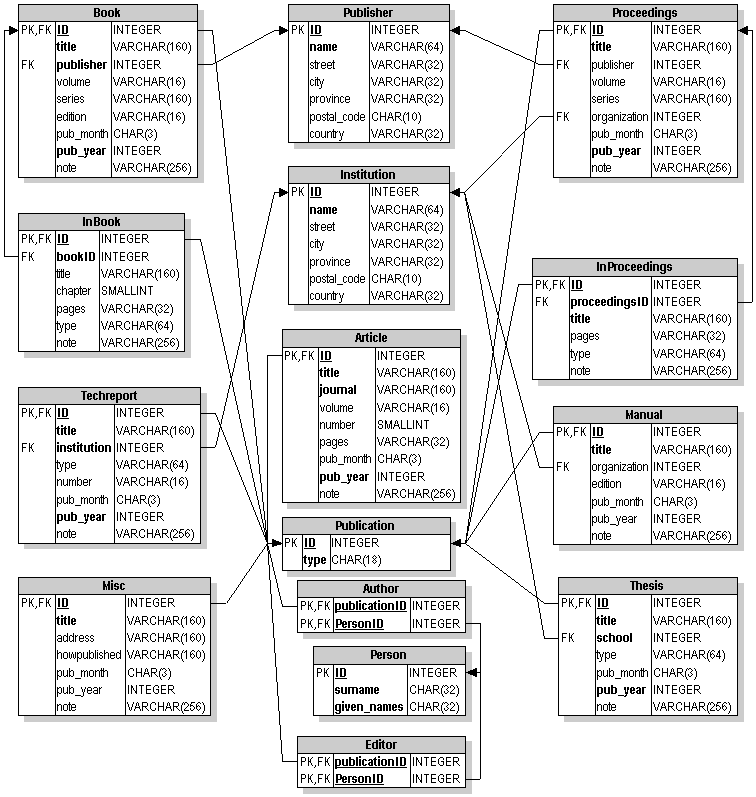
Lo scopo del database e' quello di contenere le informazioni
bibliografiche di un insieme di pubblicazioni in modo da poterle
consultare facilmente ed utilizzare per la costruzione di bibliografie
anche estese. Esso e' stato modellato sulla falsa riga del sistema
bibliografico del programma LaTeX, in modo da avere un ambiente ben
consolidato a cui far riferimento e facilitare la realizzazione di
programmi di conversione fra un sistema e l'altro.
Il significato delle relazioni che compongono il database e' il seguente:
Publication: Una generica pubblicazione. Normalmente questa relazione
viene utilizzata solamente per assegnare un identificativo univoco a
tutte le pubblicazioni presenti nel database, lasciando la
specificazione delle altre caratteristiche in relazioni specifiche per
ogni tipo di pubblicazione. Inoltre viene usata per implementare legami
complessi fra le pubblicazioni e altre relazioni. Ad esempio quella fra
una pubblicazione ed i suoi autori. Grazie alla struttura adottata si
possono avere pubblicazioni scritte da piu' autori ed autori che
scrivono piu' tipi di pubblicazioni.
Author: Rappresenta l'autore di una pubblicazione. La chiave
primaria e' composta dall'identificativo della pubblicazione e da quello
della persona; cio' garantisce l'unicita' dell'associazione fra le due
entita'.
Editor: Rappresenta il curatore di una pubblicazione. La struttura e' identica
a quella della tabella Author.
Person: Rappresenta una persona (ad esempio un autore) nel database.
Attualmente le informazioni ritenute interessanti sono solo il cognome e
il nome.
Publisher: La casa editrice di una pubblicazione.
Institution: L'istituzione (ad esempio un universita' o una software
house) responsabile di una pubblicazione.
Book: Un libro con una precisa casa editrice.
InBook: Una parte di un libro. La parte puo' essere caratterizzata da un
titolo, dal numero di capitolo o dal numero di pagina. Le informazioni
riguardanti il libro ,e quindi comuni alle sue varie parti, vengono
memorizzate nella relazione Book.
Proceedings: Gli atti di un congresso o di una conferenza.
InProceedings: Una parte degli atti di un congresso. Le informazioni
riguardanti la pubblicazione che contiene la parte sono contenute
nella relazione Proceedings.
Article: Un articolo pubblicato in un giornale o in una rivista.
Manual: Una pubblicazione di documentazione tecnica.
Techreport: Un rapporto tecnico pubblicato da una scuola o da un'altra
istituzione.
Thesis: Una tesi di laurea o di dottorato.
Misc: Una pubblicazione che non rientra in nessuna delle precedenti
categorie.
Non spieghero' il significato degli attributi che compongono le varie
relazioni, dal momento che i loro nomi sono sufficientemente
autoesplicativi. Un'unica annotazione sull'attributo "pub_month": esso e'
stato definito di tipo CHAR(3), cioe' una stringa della lunghezza fissa
di tre caratteri, e conterra' le abbreviazioni dei nomi dei mesi (le
prime tre lettere dei nomi inglesi).
I legami fra le relazioni dovrebbero essere abbastanza semplici da
capire. Come esempio per tutti verra' spiegata quello che collega la
relazione Book con la relazione Publisher. Tale legame serve per
descrivere la casa editrice di un libro. Nella relazione Book non sono
presenti tutti i dati della casa editrice, ma solo un identificativo
numerico per essa. Il numero sara' la chiave primaria della relazione
Publisher e come tale permettera' di identificare una ben precisa casa
editrice. Nella relazione Book l'attributo publisher e' una chiave
esterna verso la relazione Publisher.
Una situazione piu' complessa e' quella che coinvolge le relazioni
Publication, Author e Person; infatti in Author sono presenti due chiavi
esterne: una che identifica la pubblicazione a cui l'istanza di
relazione si riferisce, e una che permette di risalire ai dati della
persona che svolge il ruolo di autore. Ci si potrebbe chiedere quale sia
l'utilita' della relazione Publication e perche' non si sia invece stabilito
direttamente un legame fra la relazione Author e le relazioni che rappresentano i
particolari tipi di pubblicazione. La risposta e' che il modello
relazionale non permette di farlo. Infatti dal momento che un autore
puo' scrivere piu' tipi di pubblicazioni l'attributo pubblicationID
avrebbe dovuto essere una chiave esterna verso tutte le relazioni delle
pubblicazioni, ma questo non e' permesso dal momento che contraddice la
definizione stessa di chiave esterna.
Nelle successive lezioni si implementera' il database di esempio
utilizzando il linguaggio SQL standard. Lo specifico DBMS utilizzato sara'
PostgresSQL, ma sara' possibile sostituirlo con qualunque DBMS che
supporti l'Entry level dell'SQL/92.
