
Nella lezione precedente abbiamo visto come creare un entity bean e come la gestione della persistenza rimanga ancora un problema per le operazioni di scrittura del codice. La necessaria scrittura delle query e la loro esecuzione attraverso JDBC rendono tale procedura lunga e quindi potenzialmente propensa alla presenza di bug.
Vedremo, in questo capitolo, come superare questi problemi attraverso l'utilizzo degli entity bean CMP (Container Managed Persistence), in cui le operazioni di persistenza vengono gestite in maniera automatica dal container. Questa possibilità rende lo sviluppo di applicazioni, basate su sorgenti dati (tutti i sistemi informativi) particolarmente veloce, visto che non sarà più necessario doversi preoccupare di come connettersi al database e come accedere ai dati.
Prima di mostrare l'esempio pratico cerchiamo di spiegare le basi teoriche di un ECMP bean. L'idea alla base è quella di utilizzare l'astrazione, cioè, definire comportamenti astratti che in seguito verranno codificati opportunamente. Un ECMP si presenta infatti diviso in due parti: la parte che definisce le operazioni di logica e la parte che concretamente si occupa della persistenza. Chi sviluppa il bean dovrà preoccuparsi solo della prima parte, lasciando al container il compito di codificare la seconda.
Si consideri il diagramma di seguito.
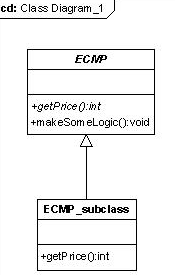
La classe ECMP espone due metodi, il primo getPrice(), che ipotizziamo si tratti di un metodo che legge un prezzo su un database, ed il secondo makeSomeLogic() che si occupa di effettuare delle operazioni di logica, utilizzando proprio il metodo .
Sia la classe che il metodo getPrice() sono astratti; in pratica abbiamo definito il comportamento del componente, senza ancora sapere bene come realizzare la logica di persistenza (metodo getPrice). A realizzarlo ci penserà ECMP_subclass, che è una classe concreta che ridefinisce il metodo getPrice(). La classe ECMP_subclass verrà realizzata dal container sulla base di indicazioni che noi forniremo nel descrittore di deploy.
Il compito dello sviluppatore di entity CMP sarà quello di definire la logica del componente, astraendo le operazioni di lettura e scrittura dati, mediante metodi astratti.
La sottoclasse creata dal container si occuperà, come detto, di definire concretamente il metodo per la lettura/scrittura dei dati. Quindi, ridefinirà i metodi ejbLoad ed ejbStore con i relativi select e update, il metodo create con relativo insert... e via discorrendo: il tutto nascosto ai nostri occhi.
Ma come fa il container a sapere quale tabella utilizzare? Come fa ad associare i campi correttamente? Gielo diremo noi attraverso il descrittore di deploy, in particolare attraverso "l'abstract persistence schema". Nell'esempio del capitolo successivo vedremo che si tratta di aggiungere al descrittore di deploy la definizione dei campi presenti nel bean. L'associazione tra questi campi e la corretta tabella e colonna di database saranno invece definiti in un ulteriore descrittore (questo dipende dal container utilizzato).
Altra domanda che ci si può porre a questo punto è: come vengono gestiti i metodi finder? In essi è possibile trovare logiche anche complesse. Bene, anche questi metodi vengono creati dalla sottoclasse, guidati dal descrittore di deploy e da un linguaggio simile ad SQL noto come EJB-QL (EJB Query Language).

