Finalmente ci avviciniamo alla progettazione di un DB e lo facciamo affidandoci alle tabelle del database Seed, che Oracle stesso mette a disposizione per scopi didattici (con esempi nella documentazione) ed utilizzando un tool di Oracle chiamato Database Configuration Assistant.
Creeremo le prime strutture logiche e fisiche di un database e configureremo le aree di memoria di base. Il procedimento che qui analizziamo può benissimo essere considerato la base per le future progettazioni di database.
Database Configuration Assistant
È un wizard, ovvero uno di quei procedimenti guidati che assistono l'utente nella creazione di un "progetto". Ci serviamo dunque del DBCA per creare le strutture logiche e fisiche di un nuovo DB. Inoltre inseriamo al suo interno uno schema d'esempio, ovvero un insieme di tabelle correlate fra loro appartenenti ad un dato utente.
Nota: quando viene creato un utente che non possiede alcuna tabella allora questo lo si indica proprio con il termine utente mentre, quando possiede almeno un oggetto, lo si indica con il termine schema. Pertanto, uno schema è un utente con tabelle o altri oggetti logici.
In Windows selezioniamo Start>Programmi>Oracle HOME>Configuration and Migration Tools>Database Configuration Assistant. La maschera di benvenuto ci informa che con questo tool non solo è possibile progettare un nuovo database, ma anche cancellare uno già esistente o modificare le sue impostazioni.
Andando avanti scegliamo l'opzione "Creare un database". Nel passaggio 2 di 8 dobbiamo selezionare un modello le cui caratteristiche saranno la base del nostro DB. Scegliamo "New Database", opzione che ci consentirà di progettarne uno generico.
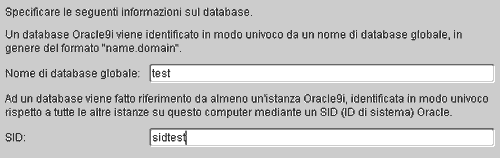
Il passaggio 3 di 8 è fra i più importanti dell'intero procedimento: dobbiamo impostare due parametri che non sarà più possibile modificare una volta creato il database. Ciascun DB Oracle è identificato in modo univoco da un nome di database globale, che ci consente di distinguerlo dagli altri DB. Questo parametro deve avere una lunghezza compresa tra 1 e 8 caratteri (vanno bene sia lettere che numeri) e non deve essere già stato utilizzato da un altro database sullo stesso computer.Il secondo parametro è il SID che identifica un'istanza Oracle in esecuzione, a sua volta collegata ad un DB. Anche il SID che stiamo inserendo non deve essere già stato associato ad un'altra istanza.. Inseriamo "test" come nome di database globale e "sidtest" come SID.
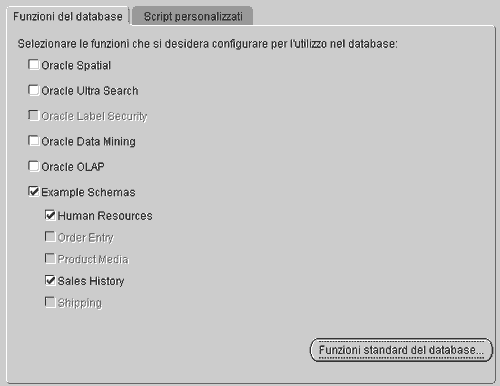
Procediamo con il passaggio 4 di 8. Qui possiamo impostare alcune funzionalità avanzate del nostro database. Il DB Oracle non è un semplice "contenitore" di dati espressi sotto forma di tabelle: alcune caratteristiche avanzate lo rendono adatto agli utilizzi più disparati. Nel nostro caso possiamo ignorare queste funzionalità ed eliminare tutto ciò che è superfluo disattivando le opzioni "Oracle Spatial" e "Oracle Ultra Search". Nel disattivare "Oracle Data Mining" e "Oracle OLAP" DBCA ci chiede se desideriamo eliminare i tablespace corrispondenti. Rispondiamo affermativamente.
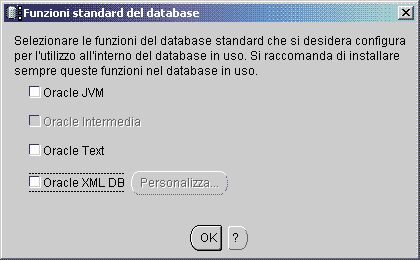
Clicchiamo quindi il pulsante "Funzioni standard del database" nella parte bassa della finestra e disattiviamo tutte le voci presenti e i tablespace relativi. La disattivazione di queste opzioni ci permette di trascurare ciò che a noi non serve e di risparmiare una notevole memoria RAM e spazio su disco.
Premiamo "OK". Le opzioni "Example Schemas", "Human Resources" e "History" rimarranno attive perché corrispondono agli schemi che utilizzeremo nel corso delle prossime lezioni.
Nel passaggio 5 di 8 dobbiamo scegliere fra "Modalità server dedicato" e "Modalità server condiviso". Scegliendo la prima opzione avremo un processo server dedicato per ciascun utente che si connette al DB, con la seconda avremo invece un numero determinato di processi server in condivisione fra tutti gli utenti connessi. Il compito di un processo server è quello di soddisfare le richieste del suo utente, ovvero caricare dati in memoria, inserire i dati nei file sul disco ed altro ancora. Scegliamo la prima opzione e procediamo.
Giungiamo al passaggio 6 di 8, composto da ben cinque sezioni, in cui vengono decise e impostate alcune caratteristiche del database e le capacità delle sue aree di memoria. Abbiamo già detto che l'SGA è formata da diverse sezioni di memoria, ognuna con un compito ben preciso. Qui possiamo decidere la dimensione di alcune di queste aree. Scegliamo l'opzione "Personalizzato" e accettiamo le dimensioni per ciascuna area.
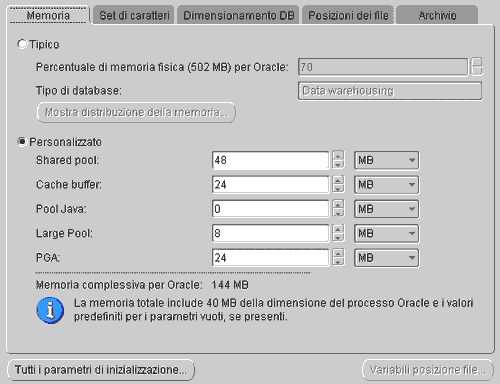
Se la capacità di memoria complessiva per Oracle è maggiore di quella libera sul sistema operativo allora le prestazioni del database non saranno ottimali (si ricorre alla memoria virtuale).
Nella sezione "Dimensionamento DB" impostiamo il valore della "Dimensione blocco", ovvero la più piccola unità logica di memorizzazione. Possiamo scegliere una capacità di blocco a partire da 2KB, ma un buon compromesso è 8KB.
Nella sezione "Posizione dei file" deselezioniamo la voce "Crea file parametri del server (spfile)". Il file dei parametri è il primo file che Oracle legge quando un'istanza è fatta partire e ne esiste uno per ogni database creato. Al suo interno sono presenti svariati parametri di inizializzazione per il corrispondente DB.
Esistono due tipi di file di parametri, modalità testo o binario. Deselezionando la voce ne creeremo uno in modalità testo il cui nome è riportato nel campo superiore. Lasciamo intatti i rimanenti parametri e anche quelli della sezione "Archivio".
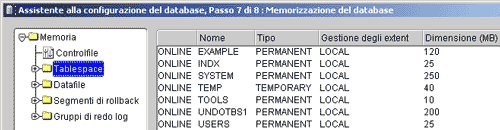
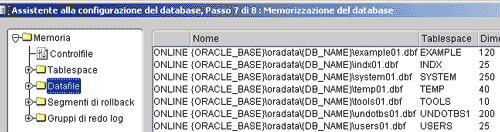
Alla fase 7 di 8, "Memorizzazione del database";, sono elencate tutte le strutture logiche e fisiche del DB che stiamo creando. Oracle ci offre la possibilità di modificare la struttura (aggiunta, modifica e cancellazione di control file, tablespace, data file e file di redo log). Non modificheremo nulla visto che non abbiamo ancora una sufficiente esperienza ma è utile esplorare ciascuna sezione, nella parte di sinistra della finestra, allo scopo di comprendere meglio la struttura del nostro database. Scopriremo infatti che Oracle per default crea
- almeno tre control file;
- sei tablespace (INDX, SYSTEM, TEMP, TOOLS, UNDOTBS1, USERS). Nel nostro caso genera anche il tablespace EXAMPLE che conterrà le tabelle di Seed;
- un data file per ciascun tablespace. Nella sezione corrispondente è elencato il nome del data file associato al suo tablespace e la relativa dimensione espressa in MB;
- tre file di redo log, anche se la denominazione corretta è gruppi di redo log file.
Nel passaggio finale, 8 di 8, abbiamo due possibilità per terminare il processo. La prima consiste nel creare al momento il DB, mentre con la seconda (opzione "Genera script di creazione del database") tutte le opzioni finora scelte vengono salvate in un apposito file di script che potremo anche eseguire in un secondo momento.
Scegliamo l'opzione "Crea database" e clicchiamo su "Fine". La durata della creazione dipende dalle caratteristiche impostate per il DB e dalla potenza del computer ospite.
Non ci rimane che fornire le password per gli utenti amministrativi SYS e SYSTEM. È buona norma:
- scegliere password differenti l'una dall'altra;
- evitare date di nascita, nomi di famiglia o qualsiasi parola di facile individuazione;
- annotarle sempre e comunque su carta.
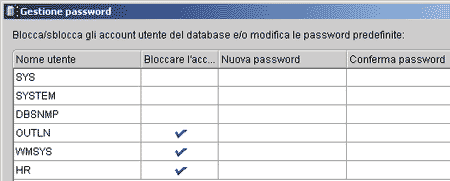
Il pulsante "Gestione password" ci mostra una lista di utenti (o account) "particolari", sia attivi sia bloccati da Oracle. L'utente HR che utilizzeremo per collegarci al database Seed risulta bloccato, lo dimostra il segno di spunta alla sua destra.