
/https://www.html.it/app/uploads/2024/11/serverless-gpu.jpg "Seeweb: Serverless GPU on demand per le applicazioni di AI")
C'è una ragione se nel corso degli ultimi anni il business di Nvidia è cresciuto talmente tanto da renderla l'azienda più capitalizzata al mondo, con un valore di mercato che si avvia a raggiungere i 4 mila miliardi di dollari. I suoi processori grafici sono infatti fondamentali per lo sviluppo e il training di modelli linguistici generativi, così come per le applicazioni basate sull'Intelligenza Artificiale. Le GPU sono diventate quindi un investimento prioritario per le aziende, non solo per i gradi colossi dell'IT come OpenAI, con gli LLM delle famiglie GPT e o1, Google (Gemini) e Meta (LLaMA).
Si calcola che entro i prossimi anni l'impiego dei Data Center registrerà un incremento di circa sei volte rispetto all'attuale richiesta di risorse computazionali. Questo significa che il trend odierno, caratterizzato da una domanda crescente di GPU con conseguente penuria di componenti e aumento dei prezzi, non potrà che accentuarsi. Esiste una soluzione per conciliare la sostenibilità economica di progetti innovativi con le esigenze di risorse e performance? Seeweb propone un modello di provisioning semplificato grazie al quale accedere on-demand a GPU server in Cloud. Questo approccio prende il nome di Serverless GPU.
Cosa è il Serverless GPU
Il Serverless GPU è un modello di computing in cui le risorse delle GPU vengono fornite in modalità serverless, quindi senza che l'utilizzatore debba gestire direttamente l'infrastruttura di base. In un contesto di questo tipo il Cloud provider ha in carico gli oneri legati all'allocazione e alla scalabilità delle risorse necessarie per eseguire applicazioni che richiedono elaborazione grafica intensiva o calcoli paralleli. Come per esempio il Deep Learning, l'analisi di Big Data e le soluzioni incentrate sulla AI.
Questo approccio presenta diversi vantaggi, a cominciare dalla scalabilità automatica. Ciò significa che le risorse GPU vengono allocate e scalate in base alle esigenze di un'applicazione. Si paga quindi soltanto per il loro consumo effettivo.
Le spese sono così basate sull'utilizzo del servizio. Ciò ottimizza e riduce i costi operativi, un vantaggio competitivo rilevante rispetto a quello che si avrebbe con un'infrastruttura on-premise, cioè sviluppata localmente. Il provider si occupa poi anche della manutenzione e dell'aggiornamento dell'hardware, ciò permette ad aziende e sviluppatori di concentrarsi su progetti e applicazioni, mantenendo il focus sulla produttività.
Il servizio Serverless GPU di Seeweb
Seeweb offre il servizio Cloud native Serverless GPU che permette di sfruttare Kubernetes, vero e proprio standard per l'orchestrazione dei container, nell'implementazione di soluzioni AI. L'utilizzatore ha la possibilità di sviluppare applicazioni e gestire task di inferenza in pochi minuti tramite il provisioning delle GPU in Cloud. Si ha poi a disposizione la compatibilità completa con qualunque ambiente Kubernetes grazie alla totale aderenza al Virtual Kubelet di Microsoft.

Tali caratteristiche lo rendono un servizio ideale per chiunque possegga già dei server per l'AI in fase di produzione e abbia la necessità di incrementare la propria capacità computazionale. Senza dovere operare migrazioni o essere costretto a ripetere il proprio lavoro da zero.
I contesti applicativi di riferimento per Serverless GPU sono numerosi. Esso garantisce infatti il supporto per la maggior parte dei servizi Managed Kubernetes pubblici (AKS, EKS, GKE..), così come per configurazioni on premise come Vanilla Kubernetes o distribuzioni Red Hat OpenShift, Tanzu Kubernetes e la container management platform Rancher.
Prerequisiti per l'uso del servizio
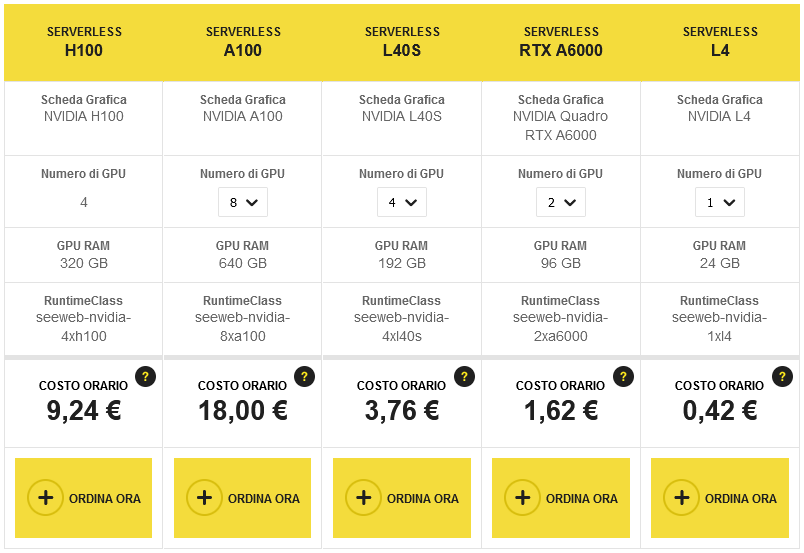
Serverless GPU permette di accedere ad un servizio Cloud native in cui i server GPU sono completamente integrabili con qualunque ambiente IT in fase di deployment. La possibilità di sfruttare Kubernetes e componenti avanzate come NVIDIA L4, RTX A6000, L40S, A100 e H100, con tariffe orarie differenti a seconda del piano scelto, permette di velocizzare la distribuzione delle applicazioni AI sul mercato. Potendo sempre contare su risorse Cloud dedicate e disponibili come se fossero in locale nel proprio cluster.
Per chi desidera iniziare ad operare con Serverless GPU il requisito richiesto è quello di aver in uso le tecnologie di Kubernetes in un ambiente preconfigurato. L'agente open source k8sGPU, scaricabile e installabile gratuitamente, permette di creare un nodo virtuale nel cluster di lavoro, creando un ponte verso le GPU disponibili in remoto.
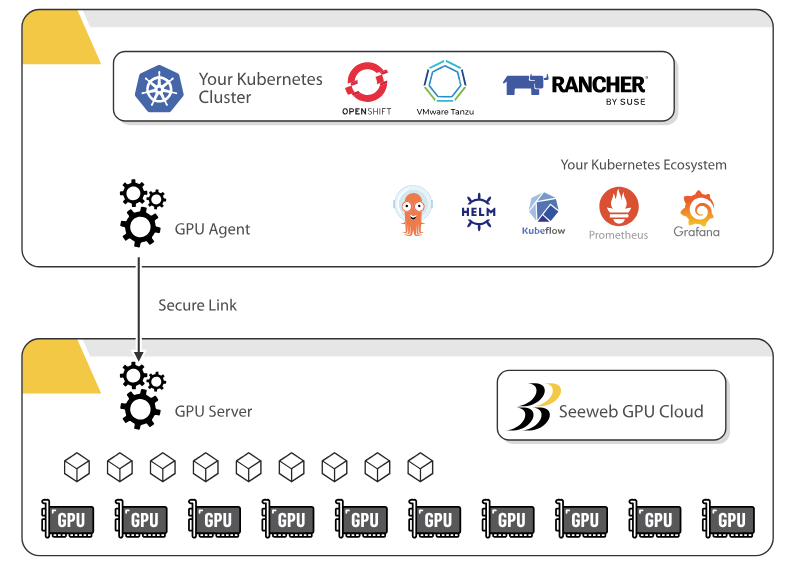
Una volta attivato il nodo virtuale si ha la possibilità di schedulare i pod per i progetti di Machine Learning e AI come si farebbe con qualunque altro worker node. k8sGPU è infatti in grado di gestire dinamicamente l'allocazione delle GPU in Cloud e i pod vengono eseguiti come se fossero stati schedulati in un cluster locale. Diventano inoltre disponibili da subito nuovi microservizi da dedicare ai task per AI ed ML.
Scalabilità illimitata con il modello di fatturazione in pay-per-use
Il modello di riferimento per la fatturazione del servizio è a consumo e per la precisione pay-per-use su base oraria. Non ci sono costi nascosti e la modalità on demand consente di pagare soltanto per le risorse utilizzate che possono essere scalate senza limiti o eliminate a seconda delle esigenze. Dal momento stesso dell'attivazione sono poi previsti dei report periodici sull'impiego delle GPU per monitorare costantemente l'entità del proprio investimento.
Le GPU sono completamente dedicate, quindi disponibili ogni volta che se ne ha la necessità, e il provisioning multi-GPU avviene in pochi secondi, offrendo la massima potenza computazionale per i carichi di lavoro delle applicazioni basate sull'AI. Tutti i piani prevedono connettività pari a 10 Gbps, assistenza tecnica da parte di esperti 24x7x365 e un uptime garantito da SLA (Service Level Agreement) fino al 99.9% per assicurare il più alto livello possibile di Business Continuity.
I piani offerti si differenziano in base alla scheda grafica disponibile, ad esempio la potente NVIDIA L4 per quello più economico fino alla NVIDIA H100 per quello più avanzato, alla quantità di GPU RAM e alla RuntimeClass di riferimento. Da un account si possono configurare uno o più provisioning serverless GPU ed utilizzarli anche per una sola ora. I piani L4, RTX A6000, L40S e A100 consentono inoltre di scegliere il numero di GPU da utilizzare, da un minimo di 1 ad un massimo di 8.
Serverless GPU opera su un'infrastruttura europea nel pieno rispetto degli standard di compliance con le normative vigenti in tema di raccolta, conservazione, protezione e trattamento dei dati personali.
Conclusioni
Lo sviluppo di applicazioni AI ed ML richiede una capacità computazionale elevata spesso destinata a crescere nel tempo, diventa quindi necessario superare i limiti delle infrastrutture on-premise in favore di soluzioni più flessibili. Seeweb offre il servizio Serverless GPU, una formula Cloud native che permette di accedere da remoto ai processori grafici da qualsiasi cluster Kubernetes. Ciò consente di estendere la propria potenza computazionale in modalità on demand, pagando unicamente per le risorse effettivamente utilizzate ed accelerando il go-to-market dei progetti AI.
/https://www.html.it/app/uploads/2025/01/Piani-cloud-storage-InternXT.jpg)
/https://www.html.it/app/uploads/2025/01/Piani-individuali-InternXT.jpg)
/https://www.html.it/app/uploads/2024/12/pcloud-1-480x300.webp)
/https://www.html.it/app/uploads/2025/01/Cloud-storage-a-vita-InternXT.jpg)