
/https://www.html.it/app/uploads/2024/02/Magika.png "Magika: l'AI di Google che riconosce i tipi di file")
Magika è un nuovo tool di Google che permette di identificare il tipo di un file tramite l'Intelligenza Artificiale. Il progetto adotta il modello generativo Keras che ha innanzitutto il vantaggio di essere molto snello, pesa infatti circa 1MB. Nonostante le dimensioni ridotte esso è in grado di rilevare il tipo di un file nel giro di pochi millisecondi. Anche nel caso in cui venga eseguito in un sistema basato su una singola CPU.
I test di Google su Magika
A dimostrazione dell'accuratezza di questo strumento, gli sviluppatori di Google riportano i risultati di un test basato sull'analisi di oltre un milione di file per più di un centinaio di content type compresi i formati binari e testuali. Alla fine della sperimentazione Magika avrebbe registrato un livello di precisione superiore al 99%. Stando così le cose esso potrebbe essere impiegato nelle applicazioni del network di Big G per rendere più sicura la user experience. Si pensi per esempio a GMail, GDrive o semplicemente a Chrome, tutte applicazioni che vengono utilizzate normalmente per visualizzare e gestire contenuti provenienti dall'esterno.
Le feature di Magika
Chi volesse volesse mettere alla prova le potenzialità di questo strumento open source può sfruttare la Web demo del progetto che è basata su una versione TFJS sperimentale. Magika è comunque disponibile anche da linea di comando tramite Python e si può interagire con le sue funzionalità attraverso delle API per lo stesso linguaggio.
Per il suo addestramento è stato utilizzato un dataset di più di 25 milioni di file per oltre 100 content type. Una volta caricato il modello dovrebbe garantire un tempo di inferenza di circa 5ms per ciascun file. Questo indipendentemente dal peso del documento scansionato in quanto il tool analizza soltanto un subset limitato di byte.
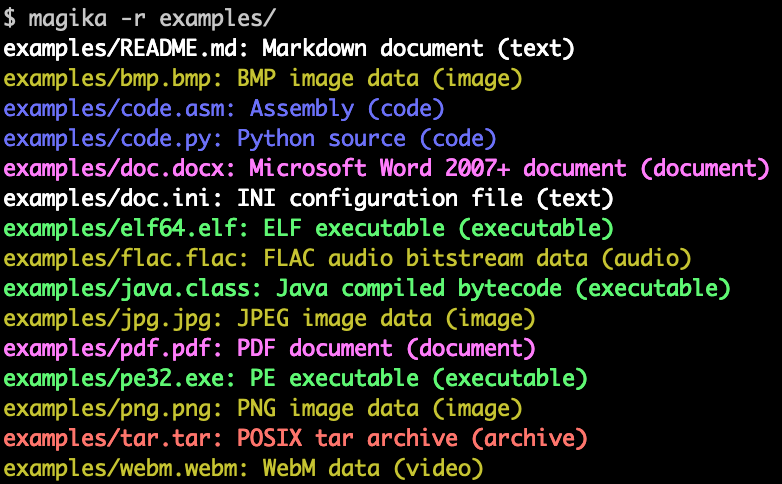
È possibile creare delle batch per analizzare più file contemporaneamente, anche un migliaio per volta. Nello steso modo si può scansionare ricorsivamente un'intera directory tramite l'opzione -r. Sono disponibili inoltre tre livelli di tolleranza agli errori, high-confidence, medium-confidence e best-guess, per settare le modalità di precisione di una scansione.
/https://www.html.it/app/uploads/2025/04/meta-AI-llama.jpg)
/https://www.html.it/app/uploads/2025/04/chatgpt-watermark.jpg)
/https://www.html.it/app/uploads/2025/04/tinder-gamer.jpg)
/https://www.html.it/app/uploads/2025/04/google-gemini-.jpg)