
SpiderFoot è un tool nato per facilitare ed automatizzare la fase di "reconnaissance" (o Information Gathering) in un Penetration Test. È lo stesso autore, Steve Micallef, a definirlo un "Footprinting Tool", con ciò intendendo il processo di acquisizione di quante più possibili informazioni su un determinato target.
In una visione più ampia, Spiderfoot può essere considerato un vero e proprio software di OSINT (Open Source INTelligence), in grado di raccogliere e correlare informazioni "pubblicamente disponibili". Oltre ad effettuare un portscan di un qualsiasi target raggiungibile via IP, infatti, SpiderFoot interroga anche una serie di "fonti aperte", come i principali Social Network (Facebook, Linkedin, Twitter ed altri), effettua uno spidering dei link lanciando query su Google direttamente dal codice, query DNS, e-mail harvesting, geolocalizzazione e molto altro.
SpiderFoot è un progetto molto attivo e già nelle prossime versioni sono previste nuove funzioni, come l'individuazione dell'ISP presso cui è ospitato il target, l'eventuale presenza all'interno di black list pubbliche (RBL), l'utilizzo dei Google Dorks, la correlazione delle varie scansioni, il supporto di proxy SOCKS e così via. Inoltre, poichè SpiderFoot è scritto quasi completamente in Python (ver. 2.6 - 2-7) è possibile, per chiunque mastichi un po' di questo straordinario linguaggio di programmazione, sviluppare moduli aggiuntivi e sottoporli ad approvazione per essere inseriti all'interno del tool, in modo tale da renderlo sempre più potente. Per maggiori informazioni, comunque, si può consultare il sito ufficiale del progetto.
Installazione e configurazione
SpiderFoot è liberamente scaricabile da Sourceforge, è Open Source e attualmente gira su Linux, Solaris, BSD e Windows. In realtà, essendo scritto in Python può essere eseguito su qualsiasi sistema UNIX-like, previa installazione dell'interprete Python e delle librerie di supporto M2Crypto, CherryPy e Mako. La procedura di installazione è comunque abbastanza semplice e ben documentata sulla Wiki disponibile su Github.
Per quanto riguarda l'ambiente Windows, invece, non c'è neanche bisogno di installare l'interprete Pyhton (nè le relative librerie) ma basta scaricare un file zippato. Dopo aver decompresso il file .zip in una directory qualsiasi, la prima cosa da fare è lanciare l'eseguibile sf.exe, che avvia sull'host locale un web server in ascolto sulla porta TCP 5001.
A questo punto, apriamo il nostro web browser e digitiamo la URL http://127.0.0.1:5001. SpiderFoot è quindi pronto a fare il suo lavoro, come mostrato in figura.
SpiderFoot in azione
Per lanciare la nostra prima scansione con SpiderFoot, clicchiamo su "New Scan" nella toolbar e inseriamo un nome descrittivo in "Scan Name" e il domain name del nostro target all'interno della textbox "Target Domain Name", come mostrato in figura Per la nostra scansione utilizzeremo un sito di test messo a disposizione da Acunetix.

Come è possibile notare, sempre in figura, grazie alla logica completamente modulare con cui è stato sviluppato SpiderFoot, è possibile utilizzare tutti i moduli spuntati di default oppure deselezionare quelli che non ci interessano e utilizzare solo gli altri.
Per il nostro test, per semplicità, scegliamo di lasciare impostati tutti i moduli, inseriamo il nome descrittivo del nostro target, l'indirizzo IP e lanciamo la scansione cliccando sul pulsante "Run Scan". A questo punto possiamo spostarci nella pagina "Scans", cliccando sul relativo pulsante nella toolbar: qui troveremo una tabella in cui ogni riga rappresenta una delle scansioni in corso (possono essere lanciate più scansioni contemporaneamente). All'interno di ogni riga troviamo una serie di campi contenenti tutte le informazioni relative alla scansione in corso, come il nome del target, l'indirizzo IP, la data e l'ora in cui è stata avviata la scansione, lo stato della scansione (running, finished, etc.), gli elementi di interesse finora trovati e, infine, un pulsante "Action" che serve per bloccare eventualmente la scansione stessa. Un esempio è mostrato in figura.
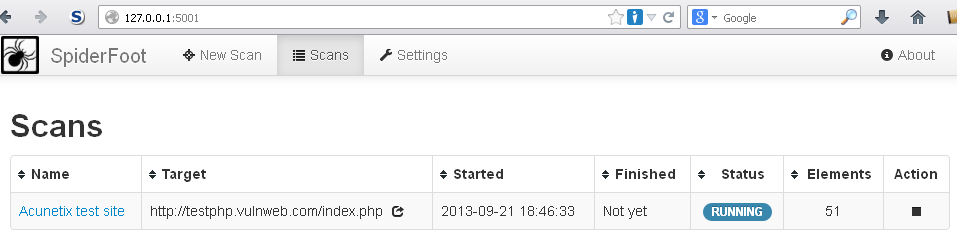
Poichè SpiderFoot è molto granulare nel suo lavoro, ci sarà da aspettare un bel po'. Il tempo di attesa dipende dal tipo e dalla complessità del target che stiamo analizzando: ad esempio, nel nostro caso il tempo impiegato è stato di circa 30 minuti. Se i tempi si allungano troppo possiamo accedere comunque ai risultati della scansione anche se questa è ancora in corso: basta cliccare sul link contenuto nel campo "Name" e otterremo una pagina dinamica contentente gli elementi finora individuati. Possiamo inoltre continuare ad aggiornare i risultati cliccando sul pulsante verde in alto a destra, come mostrato in figura

Poiché inoltre i risultati vengono salvati da SpiderFoot in un database SQLite, cliccando sul tasto blu con il simbolo del download in alto a destra, SpidereFoot ci consente anche di esportarli in un file CSV per analizzarli successivamente.
Il nostro è solo un test, per cui i risultati sono solo indicativi ma ci servono per capire la logica con cui opera SpiderFoot e le sue potenzialità. Cliccando ad esempio su "Open TCP Port Banner", troveremo tutti i tentativi di banner grabbing che SpiderFoot ha effettuato per ognuno dei servizi che ha trovato disponibili e che sono listati in "Open TCP Port". Nella nostra scansione, ad esempio, SpiderFoot ha individuato un server FTP, ovvero ProFTPD 1.3.3e Server (ProFTPD) [176.28.50.165], un server SMTP (rs202995.rs.hosteurope.de ESMTP Postfix (Ubuntu)) e un server OpenSSH (SSH-2.0-OpenSSH_5.3p1 Debian-3ubuntu7) up and running sul sito di test, come mostrato in figura.

Il banner grabbing è molto utile nella fase di reconnaissance, poiché ci permette di stabilire con precisione il tipo e la versione del servizio che gira su un determinato server e cercare eventuali vulnerabilità note e relativi exploit in grado di sfruttare tali vulnerabilità. Se si vuole effettuare una analisi ancora più approfondita e puntuale, la sezione "Log" consente di leggere ogni tentativo effettuato da SpiderFoot e relativa risposta del server.
Conclusioni
In conclusione, SpiderFoot può essere certamente considerato un buon tool da tenere a disposizione per effettuare automaticamente attività di footprinting e information gathering. La sua modularità e portabilità ne fanno certamente uno strumento flessibile e potente e, grazie alla GUI veramente user-friendly, l'utilizzo risulta davvero semplice. Il progetto, come dicevamo, è molto attivo e certamente nelle prossime versioni si arricchirà di nuove features, diventando sempre più potente. L'unica pecca forse è rappresentata dai tempi necessari per la scansione, che possono essere decisamente lunghi, ma a parte questo, si tratta certamente di un buon progetto da continuare a seguire.


