
Dopo circa due anni di assenza, torno a scrivere di SQL Server su HTML.it affrontando un argomento interessante per il programmatore: le Funzioni Definite dall'Utente.
Se siete un po' a digiuno in materia e volete prendere confidenza con il mondo di SQL Server vi dò un consiglio: leggete la guida alla programmazione in Transact-SQL pubblicata sul nostro sito.
Una panoramica sulle UDF's
In SQL Server esistono oggetti quali le viste e Le stored procedure in grado di offrire molto al programmatore Transact-SQL sia in termini di potenza che di estensibilità, sicurezza e performance. Nonostante gli indubbi vantaggi questi oggetti hanno alcune limitazioni:
- Le viste non supportano la parametrizzazione, infatti non è possibile passare alcun parametro di ingresso ad una vista (cosa che potrebbe essere utile per creare filtri particolari sulle righe selezionate dalla vista stessa)
- Le procedure memorizzate non possono essere incorporate in modo naturale all'interno di istruzioni DML, tipo una SELECT, dal momento che ritornano valori scalari o set di righe.
Per essere chiari non potremmo mai avere situazioni simili, che pure farebbero molto comodo:
/*
Chiamare una procedura memorizzata come fosse una tabella qualsiasi del nostro
database, IMPOSSIBILE!!!
*/
SELECT * FROM P_MIA_PROCEDURA
/*
Chiamare una vista in funzioni di parametri di ingresso personalizzati, IMPOSSIBILE!!!
*/
SELECT * FROM V_MIA_VISTA('PARAMETRO')
Allo scopo di superare queste limitazioni nella versione 2000 di SQL Server sono state introdotte le Funzioni definite dall'Utente (UDF), mentre nelle precedenti versioni erano disponibili solamente le Funzioni definite dal Sistema (es. GETDATE(), CHARINDEX, DATEDIFF, SUBSTRING, INSTR, ecc...).
Le UDFs vengono incorporate in istruzioni SELECT, colonne calcolate, vincoli CHECK e DEFAULT e per scrittura di codice sono molto simili alle procedure memorizzate anche se, essendo oggetti differenti, hanno una propria definizione a livello di sintassi Transact-SQL.
In questo primo articolo presentiamo una panoramica generale sulle funzionalità delle UDFs ed in seguito vedremo come integrarle attivamente nelle nostre applicazioni.
La sintassi per creare una UDF
Una UDF viene creata tramite l'istruzione CREATE FUNCTION, modificata tramite ALTER FUNCTION ed eliminata tramite DROP FUNCTION. La sintassi generale per la creazione di una UDF:
CREATE FUNCTION [owner.]nome_funzione
([@parametro_1 tipodati_1[, ...n]])
RETURNS tipodati
[WITH opzioni {Encryption|SchemaBinding} [[, ...n]]
AS
BEGIN
istruzioni
RETURN espressione
END
Nella dichiarazione di una UDF possiamo distinguere una testata e un corpo.
La testata contiene il nome della funzione, la dichiarazione dei parametri di ingresso con il tipo dati associato e la parola chiave RETURNS che identifica il tipo dati restituito dalla funzione.
Il corpo invece contiene il codice della funzione ed è compreso tra un blocco di istruzioni BEGIN ed END e termina con una istruzione RETURN.
Caratteristiche, tipi e limiti delle UDF
Per poter implementare ed utilizzare una UDF dobbiamo prima conoscerne le caratteristiche,
in sintesi ecco le principali:
- Ha sempre un identificatore sia per il sia per il nome che per il proprietario (dbo.NomeFunzione).
- Deve restituire un singolo risultato che deve essere di natura scalare otabellare. Nel caso di output scalare non sono ammessi i seguenti tipi di dati: text, ntext, image, timestamp o cursor.
- Può avere zero o più parametri di ingresso ognuno dei quali accetta tutti i tipi di dati di SQL Server 2000, fatta eccezione per timestamp, cursor e table. Per questi parametri sono ammessi valori di DEFAULT.
- Non supporta l'uso di parametri in uscita.
Le UDF si dividono in due categorie Utente e di Sistema.
Le prime ovviamente sono quelle create all'interno dei vari database utente:
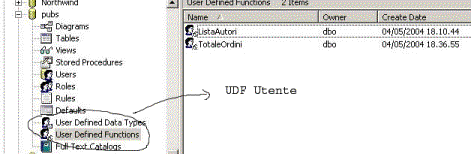
mentre le seconde sono predefinite durante l'installazione di SQL Server 2000 all'interno del database di sistema master.
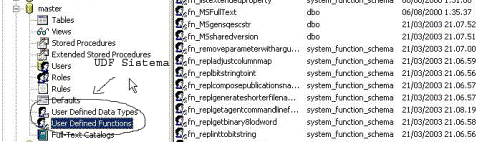
Per vedere l'elenco di tutte le funzioni presenti su SQL Server eseguite la query indicata qui sotto:
use master
go
select routine_definition AS [Sorgente], routine_name AS [Nome Funzione] from
information_schema.routines
where routine_type='Function' and routine_schema = 'system_function_schema'
È importante sottolineare che anche noi possiamo creare delle nostre funzioni utente di sistema, ma questo sarà argomento di un prossimo articolo!
Oltre alle caratteristiche di base è necessario conoscere le restrizioni legate alle UDF: il determinismo e i cosidetti "effetti collaterali".
Il determinismo
Tutte le funzioni possono dividersi in due gruppi: deterministiche e non-deterministiche.
Le prime producono sempre lo stesso risultato per gli stessi parametri di ingresso, le seconde ovviamente no. Alcuni esempi: GETDATE() è una funzione non deterministica perché ogni volta che viene invocata produce un risultato differente; DATEADD invece no, perché ogni volta che viene invocata, se i parametri di ingresso non variano, restituisce sempre lo stesso risultato.
Nella panoramica sull'uso delle UDF abbiamo accennato a come possono essere utilizzate per valorizzare le colonne calcolate all'interno di tabelle, ebbene in questo specifico caso potremmo anche aggiungere un INDICE o un vincolo PRIMARY KEY sulla stessa colonna calcolata.
Questa operazione potrebbe esserci vietata, se la UDF a cui la colonna calcolata fa riferimento non risultasse di natura deterministica. Per capire se una UDF può dirsi deterministica devono essere soddisfatte le seguenti condizioni:
- La funzione è vincolata allo schema, ciò significa che non è più possibile cambiare lo struttura degli oggetti a cui la funzione fa riferimento.
- Tutte le funzioni chiamate all'interno dell'UDF devono essere deterministiche.
- Il corpo della funzione non deve fare riferimento a nessun oggetto del database al di fuori del campo d'azione della funzione.
Nel prossimo articolo vedremo un esempio pratico di come creare un INDICE sul una colonna calcolata tramite una UDF.
Effetti collaterali
All'interno di una UDF non è possibile scrivere codice che in qualche modo alteri in modo permanente lo stato globale del sistema, perché così facendo si rischierebbe di modificare l'integrità del sistema stesso.
Le funzioni non devono avere "effetti collaterali" sul database; non devono cioè modificare nulla (scrivere su tabelle, creare oggetti, eliminare dati, ecc...) al di fuori del loro raggio d'azione. Questo significa che non possiamo utilizzare nel corpo della funzione istruzioni DML come INSERT, UPDATE, DELETE a meno che non riguardino cursori o variabili di tipo tabella usati esclusivamente all'interno della funzione (cioè locali e quindi distrutti una volta abbandonata la funzione).
Non è altresì possibile usare l'istruzione CREATE per creare oggetti anche temporanei o globali, richiamare procedure memorizzate, eseguire stringhe SQL dinamiche, utilizzare il comando RAISERROR per inviare messaggi al client oppure eseguire SELECT con la clausola FOR XML.
La regola primaria è questa: tutto ciò che avviene nella funzione non deve MAI modificare nulla all'esterno della stessa (dati, tabelle, ecc..).
Le istruzioni permesse all'interno di una UDF
Tenendo bene a mente le considerazioni fatte precedentemente ecco le istruzioni che possiamo utilizzare:
- DECLARE per definire variabili e cursori locali alla funzione
- SET per assegnare valori agli oggetti locali alla funzione
- OPEN, FETCH, CLOSE per aprire, scorrere e chiudere cursori locali alla funzione, l'importante è che le operazioni di FETCH non inviino dati al client
- IF, ELSE, WHILE, GOTO per il controllo di flusso
- SELECT per assegnare espressioni e variabili locali alla funzione
- UPDATE, INSERT, DELETE per modificare variabili di tipo tabella che sono locali alla funzione
- EXECUTE per eseguire procedure memorizzate di tipo Extended
Dopo questa panoramica tra limiti e potenzialità delle UDF siamo pronti per scrivere la nostra prima UDF.
Nel precedente articolo abbiamo introdotto l'argomento e specificato il campo d'azione delle UDFs, evidenziandone limiti e potenzialità. Ora invece ci concentreremo sul loro utilizzo pratico.
Tipi di UDF's
SQL Server 2000 supporta 3 tipologie di funzioni definite dall'utente:
- Scalari
- Valutate a livello di tabella con istruzione singola
- Valutate a livello di tabella con istruzioni multiple
Funzioni Scalari
Ogni volta che vengono invocate queste UDF restituiscono un singolo valore scalare. I valori possibili che questa funzione può restituire sono tutti i tipi di dati supportati da SQL Server eccezion fatta per BLOB, timestamp, cursor e table. La sintassi per la creazione di una funzione scalare è:
CREATE FUNCTION [owner.]nome_funzione
([@parametro_1 tipodati_1[, ...n]])
RETURNS tipodati
[WITH opzioni[, ...n]]
AS
BEGIN
istruzioni
RETURN espressione
END
Ecco invece la nostra prima funzione:
CREATE FUNCTION dbo.CalcoloVolume
(@Lung decimal (4,1), @Larg decimal (4,1), @Altezz decimal
(4,1))
RETURNS decimal (12,3) /* qui indico il tipo dati ritornato dalla funzione
*/
AS
BEGIN
RETURN (@Lung * @Larg * @Altezz)
END
GO
/* Garantisco i privilegi di esecuzione al ruolo standard PUBLIC*/
GRANT EXEC on dbo.CalcoloVolume TO PUBLIC
Come possiamo vedere la clausola RETURNS ci dice esattamente il tipo dati che la funzione restituisce. Il corpo della funzione nel nostro caso rappresentato da una singola istruzione che calcola il volume di un oggetto a partire dai parametri di ingresso, ricordiamoci però che avremmo potuto tranquillamente scrivere più istruzioni per effettuare i nostri calcoli:
CREATE FUNCTION CalcoloVolume
(@Lung decimal (4,1), @Larg decimal (4,1), @Altezz decimal (4,1)
RETURNS decimal (12,3)
AS
BEGIN
DECLARE @Vol decimal (12,3)
SET @Vol = (@Lung * @Larg * @Altezz)
RETURN @Vol
END
Anche in questo caso il risultato non cambia! Per richiamare la funzione all'interno del nostro codice Transact-SQL sarà sufficiente eseguire il codice sottostante.
/*Uso la funzione*/
SELECT dbo.CalcoloVolume(12.2,10.6,10.0)
PRINT dbo.CalcoloVolume(12.2,10.6,10.0)
Funziona tranquillamente sia con una SELECT che con una PRINT; inoltre la funzione deve essere richiamata obbligatoriamente (solo nel caso di funzioni scalari) nel formato a due parti: [nome_utente][nome_funzione]
/*Non riesco ad usare la funzione se ometto l'identificatore per il proprietario (dbo)*/
SELECT CalcoloVolume(12.2,10.6,10.0)
Server: Msg 195, Level 15, State 10, Line 1
'CalcoloVolume' is not a recognized function name.
Ad ogni istruzione RETURN deve corrispondere un valore con un tipo dati compatibile
e convertibile con quello specificato nella clausola RETURNS.
Le UDF scalari ci vengono spesso in aiuto quando vogliamo scrivere codice più leggibile e soprattutto riusabile. Incapsulare logiche di business all'interno di UDF può essere un approccio molto comodo perché assicura una adeguata flessibilità e scalabilità nella programmazione lato SQL Server.
Usare una UDF scalare sui vincoli di tipo CHECK
L'ANSI SQL permette di utilizzare delle sottoquery all'interno di vincoli di tipo CHECK, ma sfortunatamente SQL Server 2000 non supporta questa funzionalità. Grazie all'uso delle UDFs però possiamo aggirare l'ostacolo.
Supponiamo di voler validare una regola di questo tipo: data una tabella T0 contente una colonna ColREF, vogliamo che i valori inseriti in questa colonna siano già contenuti nella colonna ColKEY presente in una delle due tabelle correlate T1,T2.
Il codice completo dell'esempio è allegato nello zip dell'articolo, vediamo invece il codice della funzione e l'aggiunta del vincolo CHECK:
CREATE FUNCTION dbo.CHECK_ColREF
(@CHIAVE int)
RETURNS bit
AS
BEGIN
IF EXISTS(SELECT *
FROM T1
WHERE ColKEY
= @CHIAVE)
RETURN 1
IF EXISTS(SELECT *
FROM T2
WHERE ColKEY
= @CHIAVE)
RETURN 1
RETURN 0
END
/* Aggiungo il vincolo CHECK */
ALTER TABLE T0
ADD CONSTRAINT CHK_ColREF_Da_ColKEY
CHECK(dbo.CHECK_ColREF(ColREF) = 1)
In questo modo se inseriamo in T0 un valore che non è contenuto né in T1 né in T2 avremo una risposta simile a questa:
Server: Msg 547, Level 16, State 1, Line 1
INSERT statement conflicted with COLUMN CHECK constraint 'CHK_ColREF_Da_ColKEY'.
The conflict occurred in database 'tempdb', table 'T0', column 'ColREF'.
The statement has been terminated.
Usare una UDF per affrontare questo problema è una soluzione molto più elegante e performante rispetto all'uso di triggers.
Usare una UDF scalare in colonne calcolate
Le funzioni scalari possono essere utilizzate all'interno di campi calcolati. Supponiamo ad esempio di avere la tabella DIMENSIONI contente le tre dimensioni (lunghezza, larghezza e altezza) di ipotetici oggetti. In questa caso potremmo creare una colonna calcolata dal nome volume, nel quale utilizziamo la funzione CalcoloVolume per avere direttamente nella tabella DIMENSIONI il valore del volume. Ecco il codice:
CREATE TABLE DIMENSIONI
(
lunghezza decimal (4,1),
larghezza decimal (4,1),
altezza decimal (4,1),
volume AS ( dbo.CalcoloVolume(lunghezza,larghezza,altezza)
)
)
GO
INSERT INTO DIMENSIONI (lunghezza,larghezza,altezza)
SELECT 10.0,13.0,12.4
INSERT INTO DIMENSIONI (lunghezza,larghezza,altezza)
SELECT 10.0,10.0,12.4
INSERT INTO DIMENSIONI (lunghezza,larghezza,altezza)
SELECT 7.0,16.0,12.4
SELECT * FROM DIMENSIONI
I vantaggi di questa soluzione sono molteplici ad esempio la possibilità di fare query che richiamano in causa direttamente il volume, il che risulta molto elegante.
SELECT * FROM DIMENSIONI WHERE volume>10
rispetto alla tipica
SELECT * FROM DIMENSIONI WHERE (lunghezza*altezza*larghezza)>10
Indicizzare una colonna calcolata con una UDF
Ricordiamoci che se la funzione è deterministica possiamo anche indicizzare la colonna calcolata, l'unico requisito è quello di applicare alla funzione l'opzione WITH SCHEMABINDING.
/* Riscrivo la funzione aggiungendo l'opzione with schemabinding
*/
CREATE FUNCTION dbo.CalcoloVolume
(@Lung decimal (4,1), @Larg decimal (4,1), @Altezz decimal (4,1))
RETURNS decimal (12,3)
WITH SCHEMABINDING /*Posso indicizzare la colonna volume*/
AS
BEGIN
RETURN (@Lung * @Larg * @Altezz)
END
/* Associo un indice alla colonna calcolata volume */
CREATE INDEX [IDX_VOLUME] ON [dbo].[DIMENSIONI]([volume])
Così facendo abbiamo creato un legame esplicito tra i due oggetti: la funzione CalcolaVolumee la tabella DIMENSIONI, questo implica che prima di poter eliminare la funzione dobbiamo rimuovere tutti i riferimenti agli oggetti ad essa collegati.
Creare una lista di Autori
Tramite le UDFs è molto semplice anche creare una lista di elementi in formato csv, ad esempio Mario Rossi, Gino Verdi, Luigi Bianchi. I passi per produrre questa lista sono:
- selezionare i dati tramite una SELECT opportuna
- scorrere il set di righe restituito e concatenare in una variabile stringa i valori opportunamente separati da virgola
Allo scopo ho utilizzato il database pubs di SQL Server, per creare la lista degli autori dato un identificativo per il titolo:
USE pubs
GO
CREATE FUNCTION dbo.ListaAutori(@TitoloID varchar(6))
RETURNS varchar(8000)
AS
BEGIN
DECLARE @Autori varchar(8000)
SELECT @Autori = ISNULL(@Autori + ', ', '') +
authors.au_fname + ' ' + authors.au_lname
FROM titleauthor INNER JOIN
authors ON titleauthor.au_id = authors.au_id
WHERE titleauthor.title_id = @TitoloID
RETURN @Autori
END
GO
/* Garantisco i privilegi di esecuzione al ruolo standard PUBLIC*/
GRANT EXEC on dbo.ListaAutori TO PUBLIC
GO
/* proviamo la funzione */
SELECT dbo.ListaAutori('BU1111')
/*ecco il risultato*/
Michael O'Leary, Stearns MacFeather
/*oppure la lista csv degli autori per ogni singolo titolo*/
SELECT dbo.ListaAutori(title_id) FROM dbo.titles
Veramente molto comodo, nessuna concatenazione lato client, meno codice e più ordine nelle pagina ASP o ASP.NET!
Funzioni valutate a livello di tabella con istruzione singola
Le funzioni di questo tipo possono essere considerate viste parametrizzate. Il corpo contiene una unica istruzione SELECT generalmente accompagnata da una clausola WHERE in cui sono presenti criteri di ricerca basati sui parametri di ingresso della funzione. Ecco la sintassi per la creazione di una funzione inline con istruzione singola:
CREATE FUNCTION [owner.]nome_funzione
([@parametro_1 tipodati_1[, ...n]])
RETURNS TABLE
[WITH opzione[, ...n]]
AS
RETURN SELECT * FROM TABELLA [WHERE ...]
Queste funzioni restituiscono sempre una set di righe (rowset) tramite variabili di tipo tabella come indicato dalla parola chiave RETURNS. Vediamo un esempio:
/*Creo la funzione*/
CREATE FUNCTION OrdiniClienti(@ClienteID varchar(5))
RETURNS TABLE
AS
RETURN SELECT * FROM dbo.Orders WHERE CustomerID=@ClienteID
GO
/*Richiamo la funzione, posso omettere il nome del proprietario tipicamente dbo*/
SELECT C.ContactName,CO.* FROM OrdiniClienti('HANAR') CO
JOIN dbo.Customers C ON C.CustomerID=CO.CustomerID
Come possiamo vedere la funzione OrdiniClienti può essere considerata alla stregua di una vista vera e propria. Per richiamare questo tipo di funzioni, a differenza di quelle scalari, possiamo omettere il nome del proprietario della funzione, tipicamente dbo (cioè l'owner del database).
Funzioni valutate a livello di tabella con istruzione multipla
A differenza delle precedenti non ritornano semplicemente il risultato di una singola istruzione SELECT. La parola chiave RETURNS dichiara una variabile di tipo tabella che viene generalmente riempita dalle istruzioni contenute nel corpo della funzione. Ecco la sintassi per la creazione di una funzione inline con istruzioni multiple:
CREATE FUNCTION [owner.]nome_funzione
([@parametro_1 tipodati_1[, ...n]])
RETURNS @variabile_tabella TABLE definizione_della_tabella
[WITH opzioni[, ...n]]
AS
BEGIN
istruzioni
RETURN
END
GO
A differenza delle altre tipologie di funzioni, qui RETURN viene sempre chiamata come ultima istruzione del corpo delle funzione ma non abbinata nessun valore, in quanto è la tabella definita in RETURNS ad essere sempre restituita come risultato finale dalla nostra funzione.
Un esempio molto interessante: F_SPLITTA_STRINGA
Il più delle volte vi sarete posti il problema di passare da una pagina ASP un array di valori, come parametro di ingresso, ad una stored procedure. Allo scopo di risolvere questo problema, nel codice allegato all'articolo, vi è la funzione F_SPLITTA_STRINGA.
Questa funzione emula la classica Split() di Visual Basic, partendo da una lista di valori separati da virgola o altro genere, produce come risultato una tabella di valori con una strutttura simile:
@TABELLA_RESTITUITA TABLE (INDICE SMALLINT PRIMARY KEY, VALORE VARCHAR(8000))
Ecco alcuni esempi di utilizzo di questa funzione:
DECLARE @LISTA_AUTORI VARCHAR(8000)
SET @LISTA_AUTORI = '172-32-1176,213-46-8915,238-95-7766'
SELECT * FROM dbo.F_SPLITTA_STRINGA(@LISTA_AUTORI,',')
/*Può essere usata in una JOIN*/
SELECT A.* FROM dbo.authors A
JOIN dbo.F_SPLITTA_STRINGA(@LISTA_AUTORI,',') LA
ON A.au_id=LA.VALORE
/*Può essere usata in una DELETE*/
DELETE FROM dbo.authors WHERE au_id IN
(SELECT VALORE dbo.F_SPLITTA_STRINGA(@LISTA_AUTORI,DEFAULT))
/*Può essere usata in una UPDATE*/
UPDATE dbo.authors SET contract=0
FROM dbo.authors A, dbo.F_SPLITTA_STRINGA(@LISTA_AUTORI,DEFAULT) LA
WHERE A.au_id=LA.VALORE
La funzione accetta due parametri di ingresso, la lista dei valori da "splittare" e il separatore, di default è impostato la virgola e restituisce una tabella a due colonne, in cui troviamo la posizione e il valore dell'elemento separato nella lista.
Le performance delle UDFs
Se la comodità di incapsulare codice SQL al'interno delle UDF è grande, non sempre possiamo dire delle performance. Difatti prima di iniziare a sostituire in modo massivo viste e procedure memorizzate con le più "fresche" UDFs bisogna pensarci un attimo. I casi vanno valutati volta per volta. Un esempio: la funzione dbo.TotaleOrdini si occupa di calcolare il totale di un ordine partendo da uno specifico ID Ordine.
USE Northwind
GO
CREATE FUNCTION dbo.TotaleOrdini(@OrdineID int)
RETURNS money AS
BEGIN
RETURN(
SELECT CAST(
SUM(UnitPrice * Quantity * (1 - Discount)) AS money)
FROM [Order Details]
WHERE OrderID = @OrdineID
)
END
GO
/*CASO 1 - eseguo la query usando la funzione personalizzata per calcolare il
totale*/
SELECT OrderID, dbo.TotaleOrdini(OrderID) AS OrderTotal FROM Orders ORDER BY OrderID
/*CASO 2 - eseguo la query calcolando direttamente nell SELECT il totale con la
formula prestabilita*/
SELECT OrderID, CAST(SUM(UnitPrice * Quantity * (1 -Discount)) AS money) AS OrderTotal
FROM [Order Details] GROUP BY OrderID ORDER BY OrderID
In entrambi i casi il risultato è lo stesso, sul mio PC 830 righe, con una differenza nel caso 2 il l'esecuzione della query è almeno 10/15 volte più veloce! Chiediamoci il perché?
Nel caso 1 il numero di letture I/O è notevolmente maggiore, perché per ogni riga della query (cioè ogni volta che invochiamo la funzione) SQL Server deve effettuare delle letture/accessi addizionali sulle pagine dati della tabella Order Details.
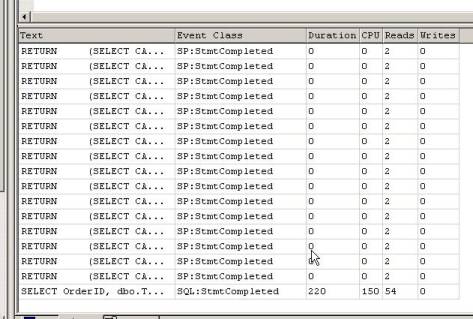
Nel secondo caso invece il numero di letture è notevolmente minore perché SQL Server accede ad ogni pagina dati una volta sola!
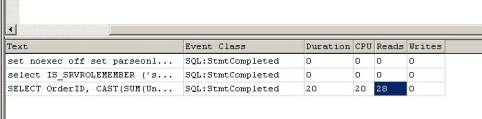
Le immagini fanno riferimento al tracciamento lato server delle due query.
Conclusione
Spero che la panoramica fatta in questo articolo possa esservi stata utile per comprendere le potenzialità dell'uso delle UDF all'interno della programmazione Transact-SQL in SQL Server.
La prossima volta affronteremo il problema di come trasformare una UDF scritta da noi in una UDF di sistema, rendendola così accessibile da tutti i database utente!
