
Abbiamo già introdotto la specifica JPA 2.0 (Java Persistence API) per l'accesso e la persistenza dei dati tra oggetti Java e database relazionali. Nel precedente articolo abbiamo introdotto il quadro generale della persistenza in Java e abbiamo confrontato i meccanismi alla base della specifica JPA con quelli di Hibernate una delle principali implementazioni della specifica.
In questo articolo si approfondirà il meccanismo di generazione automatica delle chiavi e si introdurrà un nuovo argomento: come rendere persistenti le relazioni tra oggetti. Vedremo che ci sono diversi tipi di annotazione per descrivere le varie forme di relazione che modellano la realtà.
Infine, vedremo che non è necessario dover ricorrere a molteplici entità per descrivere alcune relazioni, è possibile infatti rendere persistenti diversi oggetti compattando le informazioni su un'unica entità matrice. Per riassumere ci occuperemo di:
- Generazione automatica delle chiavi
- Relazioni e molteplicità
- Classi Embeddable
Per seguire gli esempi che faremo occorre avere installato sul computer il Java Development Kit (JDK 6). Si assume che sia stata impostata la variabile d'ambiente JAVA_HOME
Inoltre si consiglia dell'articolo JPA 2 e la persistenza in Java HyperSQL
Generazione automatica delle chiavi
Iniziamo con la gestione delle chiavi primarie per assicurare l'univocità delle tuple e quindi degli oggetti resi persistenti. Per formare la chiave primaria è possibile utilizzare i dati della logica di business, oppure ricorrere a valori numerici generati automaticamente. Probabilmente così si eviterà di ricorrere a chiavi composite ma si dovrà utilizzare un campo apposito.
L'annotazione che ci permette di realizzare la generazione automatica delle chiavi è
@GeneratedValueQuesta annotazione va usata necessariamente assieme all'annotazione @Id
persistence provider
Per definire la strategia di generazione della chiave si usa l'opzione GenerationType. Ecco le strategie disponibili in JPA 2.
GenerationType.IDENTITY
Questa strategia consente al persistence provider di fornire un valore basandosi su una colonna identità del database. Ad esempio, il database può gestire delle variabili contatore per stabilire il valore da assegnare alla chiave della nuova tupla, oppure può fornire il valore più basso tra quelli non assegnati, il comportamento può variare in base all'implementazione della specifica JPA e al RDBMS utilizzato.
Di seguito esaminiamo un esempio che mostra come è applicata questa strategia in Hibernate/HSQLDB. Per l'organizzazione del progetto fare riferimento all'articolo precedente. È possibile trovare, in allegato all'articolo, gli esempi che seguono e il file persistence.xml.
Car
package autogenandrel;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Car{
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
private String nomeMacchina;
public Car(){}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getNomeMacchina() {
return nomeMacchina;
}
public void setNomeMacchina(String nomeMacchina) {
this.nomeMacchina = nomeMacchina;
}
public String toString(){
return "ID: " + getId() + " - Nome: " + getNomeMacchina();
}
}La logica di persistenza si avvale della classe LogicaJPA, classe già approfondita nell'articolo precedente. Utilizzeremo questa classe anche negli esempi a seguire.
JPALogic
package JPALogic;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import javax.persistence.Query;
public class LogicaJPA {
private EntityManagerFactory emf;
private EntityManager em;
public LogicaJPA(String persistenceUnitName){
emf = Persistence.createEntityManagerFactory(persistenceUnitName);
em = emf.createEntityManager();
}
public void jpaCreate(Object obj){
em.getTransaction().begin();
em.persist(obj);
em.getTransaction().commit();
em.detach(obj);
}
public Query jpaRead(String query){
Query q = em.createQuery(query);
return q;
}
public void jpaUpdate(Object obj){
em.getTransaction().begin();
em.merge(obj);
em.getTransaction().commit();
em.detach(obj);
}
public void jpaDelete(Object obj){
em.getTransaction().begin();
Object managed = em.merge(obj);
em.remove(managed);
em.getTransaction().commit();
}
public void closeLogicaJPA(){
em.close();
emf.close();
}
}Segue un semplice main. Si ipotizza di utilizzare un database HSQLDB avviato esternamente in modalità server.
package autogenandrel;
import java.util.List;
import JPALogic.LogicaJPA;
public class MainAutoID {
public static void main(String[] args) {
LogicaJPA logJPA = new LogicaJPA("testhsqldb");
Car car1 = new Car();
car1.setNomeMacchina("Car1");
logJPA.jpaCreate(car1);
Car car2 = new Car();
car2.setNomeMacchina("Car2");
logJPA.jpaCreate(car2);
List<Car> listaPers3 = logJPA.jpaRead("select t from Car t").getResultList();
System.out.println("Oggetti resi persistenti:");
for(int i=0;i<listaPers3.size();i++){
System.out.println(listaPers3.get(i).toString());
}
}
}Dalla prima esecuzione otterremo:
Oggetti resi persistenti:
* ID: 1 - Nome: Car1
* ID: 2 - Nome: Car2Dopo la seconda:
Oggetti resi persistenti:
* ID: 1 - Nome: Car1
* ID: 2 - Nome: Car2
* ID: 3 - Nome: Car1
* ID: 4 - Nome: Car2L'assegnazione del valore all'attributo matricola è sequenziale. Cancellando tutte o parte delle tuple, il valore assegnato non ripartirà da zero o dal primo valore disponibile, ma dall'ultimo valore non assegnato. È possibile pertanto avere dei vuoti nei valori assegnati in seguito all'esecuzione di operazioni di delete. L'aspetto è però sfruttabile per disporre di un ordinamento temporale tra le tuple registrate.
Occorre tener presente che invocare il solo metodo persist sull'oggetto non implica l'assegnazione dell'ID, l'ID viene assegnato solo al flush time, ossia al momento dell'effettiva registrazione dell'oggetto nel database, ad esempio in seguito a un commit.
In generale, il valore che verrà assegnato segue politiche determinate dal database utilizzato.
GenerationType.SEQUENCE
Il persistence provider assegna un valore in base ad una sequenza registrata nel database. A seconda della particolare implementazione usata, può essere necessario o meno definire una sequenza nel database.
Con Hibernate e HSQLDB non è necessario, occorrerà però definire un'annotazione SequenceGenerator. Spesso viene posizionata nella stessa entità in cui è utilizzata la sequenza, ma non è necessario in quanto l'annotazione è definita a livello globale.
@SequenceGenerator(name="seq", initialValue=1, allocationSize=5)I parametri dell'annotazione sono un'identificativo, un valore di partenza della sequenza e la dimensione dell'allocazione. A differenza della strategia IDENTITY l'assegnazione dell'ID avviene al momento in cui è invocato il metodo persist
flush time
Gli ID vengono allocati in gruppo, in una quantità definita dal valore allocationSize. Ciò riduce la necessità di dialogare con il database per ottenere gli ID, diminuendo il tempo richiesto, ma implica che alcuni ID potrebbero non essere usati, per cui è probabile che vi sarà un gap nella sequenza dei valori effettivamente impiegati.
L'annotazione per la definizione della strategia di generazione dei valori sarà:
@GeneratedValue(strategy=GenerationType.SEQUENCE, generator="seq")Realizziamo una nuova entità, chiamandola ad esempio "Car2
...
@Entity
@SequenceGenerator(name="seq", initialValue=1, allocationSize=5)
public class Car2 {
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE, generator="seq")
private long matricola;
...Rieseguendo il main
select t from Car2 t
Car2
Car
Oggetti resi persistenti:
* Id: 1 - Nome: Car1
* Id: 2 - Nome: Car2
* Id: 5 - Nome: Car1
* Id: 6 - Nome: Car2La prima esecuzione ha riservato i primi cinque valori della sequenza, pur senza utilizzarli tutti. È stato riservato anche lo 0
1
La seconda esecuzione partirà dal primo valore non riservato, nel nostro caso 5, da qui il gap osservabile. Una successiva sequenza esecuzione partirebbe da 10 e così via.
In HSQLDB è possibile trovare le sequenze generate in una tabella di sistema (View/Show system tables), alla voce "INFORMATION_SCHEMA.SYSTEM_SEQUENCES"
Esplorandone il contenuto si vedrà che la sequenza generata dal persistence provider è registrata come "HIBERNATE_SEQUENCE".
È possibile eliminarla con il comando
DROP SEQUENCE "PUBLIC"."HIBERNATE_SEQUENCE"È anche possibile farla ripartire da un valore X
ALTER SEQUENCE "PUBLIC"."HIBERNATE_SEQUENCE" RESTART WITH XOccorre però fare attenzione che la sequenza così modificata non fornisca valori già utilizzati, nel qual caso i valori assegnati violerebbero il vincolo di integrità, con il risultato di bloccare l'aggiornamento del database (e forse perdere dati).
GenerationType.TABLE
Il persistence provider assegna un valore in base ad una tabella registrata nel database. In modo analogo alla strategia SEQUENCE possiamo utilizzare un'annotazione per definire la tabella:
@TableGenerator(name="tab", initialValue=0, allocationSize=5)Da notare che questa volta il valore iniziale è 0 in quanto con questa strategia il valore memorizzato è quello appena usato (o inizializzato), mentre nella strategia SEQUENCE il valore memorizzato è il prossimo da usare.
Per il resto la strategia è analoga al caso precedente. Alcune implementazioni non prevedono di avere una tabella effettiva memorizzata nel database e si basano su una sequenza, per cui la differenza con la precedente strategia è veramente minima. La strategia è stata prevista in quanto non tutti i RDBMS prevedono la possibilità di fornire sequenze.
L'annotazione per la generazione dei valori sarà:
@GeneratedValue(strategy=GenerationType.TABLE, generator="tab")GenerationType.AUTO
In questo caso è il persistence provider a stabilire un'apposita strategia di generazione della chiave, scegliendola tra quelle viste finora. È utile pertanto ricorrere alla documentazione del fornitore del framework che implementa la specifica per sapere che strategia verrà utilizzata.
Una strategia di default potrebbe essere basata sull'opzione IDENTITY. Alcune implementazioni o RDBMS inoltre potrebbero stabilire un comportamento leggermente differente tra le strategie AUTO e IDENTITY. Un esempio viene da ObjectDB. Mentre alla prima viene associato un generatore globale che fornisce un identificatore univoco e mai riciclato a livello di database, la seconda associa un generatore a ogni entità. Un buon esempio di come possano esistere molteplici comportamenti partendo dalla stessa specifica.
Nella prossima sezione ci occuperemo di come gestire le relazioni e le relazioni multiple.
Relazioni e molteplicità
Gli oggetti possono contenere uno o più riferimenti ad altri oggetti, questi riferimenti prendono il nome di relazione.
Le relazioni hanno diverse caratteristiche, la prima è la direzionalità, una relazione potrà essere:
- unidirezionale
- bidirezionale
Altra caratteristica da prendere in considerazione è l'opzionalità. Non è detto che la relazione debba esistere necessariamente. Se non è obbligatoria, la relazione si dice opzionale.
Infine vi è la molteplicità della relazione. La relazione può sussistere verso uno o più oggetti, in entrambe le direzioni. Si identificano pertanto tre tipi di relazioni:
uno a unouno a moltimolti a molti
Le API JPA permettono di gestire le relazioni e di risparmiarci di scrivere molto codice.
Relazione uno a uno unidirezionale
Per tener traccia dell'entità riferita, si utilizza l'annotazione @OneToOne. Se si è intenzionati a realizzare un'associazione unidirezionale l'annotazione comparirà solo nell'entità che possiede il riferimento, come nell'esempio seguente che prende in considerazione una classe Person che fa riferimento alla classe Car realizzata in precedenza.
Person
package autogenandrel;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.OneToOne;
@Entity
public class Person{
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
private String nome;
@OneToOne
private Car macchina;
public Person(){}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getNome() {
return nome;
}
public void setNome(String nome) {
this.nome = nome;
}
public Car getMacchina() {
return macchina;
}
public void setMacchina(Car macchina) {
this.macchina = macchina;
}
public String toString(){
return "ID: " + getId() + " - Nome: " +
getNome() + "n Macchina:n" +
" " + macchina.toString();
}
}Segue un semplice main per testare il comportamento delle entità.
package autogenandrel;
import java.util.List;
import JPALogic.LogicaJPA;
public class MainUnidir {
public static void main(String[] args) {
LogicaJPA logJPA = new LogicaJPA("testhsqldb");
Car car = new Car ();
car.setNomeMacchina("313");
logJPA.jpaCreate(car);
Person person = new Person ();
person.setNome("Paperino");
person.setMacchina(car);
logJPA.jpaCreate(person);
List<Person> listaPerson = logJPA.jpaRead("select t from Person t").getResultList();
System.out.println("Oggetti resi persistenti:");
for(int i=0;i<listaPerson.size();i++){
System.out.println(listaPerson.get(i).toString());
}
logJPA.closeLogicaJPA();
}
}Nel database sarà creata una tabella per ognuna delle due entità, se ancora non presente. Nella tabella relativa all'entità Person sarà presente un campo CARNAME_ID contenente la chiave esterna necessaria a identificare l'entità associata a ogni tupla.
L'annotazione @JoinColumn consente di personalizzare il nome della colonna (name="nomeColonna"), di specificare se non è possibile aggiornare il riferimento (updatable="false"), o di specificare il nome della chiave primaria della tabella cui si fa riferimento (referencedColumnName="NomeColonnaRiferita").
È possibile anche effettuare il mapping verso chiavi esterne composite, in questo caso si utilizzerà l'annotazione @JoinColumns(), ponendo all'interno delle parentesi le annotazioni @JoinColumn che fanno riferimento ai singoli campi della chiave composita.
Eseguendo il main, dopo aver inizializzato due oggetti e averli resi persistenti, avviene una lettura dal database. Vengono richiesti gli oggetti dell'entità Person e si potrà vedere che le entità caricate dal database già contengono il riferimento all'oggetto puntato al momento in cui sono state rese persistenti. Pertanto nel momento in cui avviene la lettura dal database viene effettuato automaticamente il join tra le tabelle Person e Car.
Questo è uno dei vantaggi offerti da JPA. Non dovremo preoccuparci di caricare gli oggetti di ogni singola entità e di popolarne i riferimenti, sarà sufficiente caricare dal database le entità che contengono i riferimenti e in automatico verranno caricate nella memoria Java gli oggetti riferiti resi persistenti con le rispettive associazioni.
"Cascade" è un'opzione utile dell'annotazione @OneToOne (e delle annotazioni @OneToMany, @ManyToMany e @ManyToOne che vederemo successivamente). Definisce un insieme di operazioni propagate all'entità associata. Solitamente è utilizzato per operazioni come Persist, Merge, Remove, Refresh e Detach (All, se si desidera verso tutte).
Relazione uno a uno bidirezionale
Per introdurre una relazione bidirezionale occorre modificare la classe Car. È possibile procedere aggiungendo l'attributo Person person insieme all'annotazione @OneToOne alla classe Car, ma ciò comporterà la modifica della tabella CAR nel database.
Un'altra possibilità, seguita nell'esempio seguente, è quella di introdurre due nuove classi, CarBidir e PersonBidir. Di seguito si riportano le differenze significative con le classi precedenti (è possibile trovare gli esempi completi nell'archivio associato all'articolo):
...
public class CarBidir {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
private String nomeMacchina;
@OneToOne
private PersonBidir person;
public CarBidir(){}
public PersonBidir getPerson() {
return person;
}
public void setPerson(PersonBidir person) {
this.person = person;
}
...
...
public class PersonBidir {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
private String nome;
@OneToOne
private CarBidir macchina;
...Apportiamo di conseguenza le modifiche al main.
package autogenandrel;
import java.util.List;
import JPALogic.LogicaJPA;
public class MainBidir {
public static void main(String[] args) {
LogicaJPA logJPA = new LogicaJPA("testhsqldb");
CarBidir car = new CarBidir();
car.setNomeMacchina("313");
logJPA.jpaCreate(car);
PersonBidir person = new PersonBidir();
person.setNome("Paperino");
logJPA.jpaCreate(person);
person.setMacchina(car);
logJPA.jpaUpdate(person);
car.setPerson(person);
logJPA.jpaUpdate(car);
List<PersonBidir> listaPerson = logJPA.jpaRead(
"select t from PersonBidir t").getResultList();
System.out.println("Oggetti resi persistenti:");
for(int i=0;i<listaPerson.size();i++){
System.out.println(listaPerson.get(i).toString());
}
logJPA.closeLogicaJPA();
}
}Importante osservare che i riferimenti sono aggiornati solo dopo avere reso persistenti gli oggetti. Se si cerca di rendere persistenti le classi dopo aver inizializzato anche i riferimenti si ottiene un messaggio di errore, (object references an unsaved transient instance), in quanto uno dei due oggetti puntati si trova ancora in stato transiente, di conseguenza non costituisce un riferimento valido per il database.
Una soluzione alternativa a quella presentata, volendo rendere persistenti gli oggetti dopo aver inizializzato anche i riferimenti e di conseguenza senza necessità di modificare gli oggetti già inseriti nel database, è quella di racchiudere le operazioni in un'unica transazione JPA:
...
EntityManagerFactory emf = Persistence.createEntityManagerFactory("testhsqldb");
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
CarBidir car = new CarBidir();
car.setNomeMacchina("313");
PersonBidir person = new PersonBidir();
person.setNome("Paperino");
person.setMacchina(car);
car.setPerson(person);
em.persist(car);
em.persist(person);
em.getTransaction().commit();
em.close();
emf.close();
...Relazione uno a molti
Quando un'entità può essere associata a più di un oggetto dello stesso tipo sussiste una relazione del tipo uno a molti. Analogamente al caso precedente la relazione può essere uni o bidirezionale, approfondiremo con un esempio il secondo caso.
Le annotazioni usate sono:
- @OneToMany
- @ManyToOne
Come esempio si propone una nuova versione estesa delle classi Person e Car, tenendo in conto che una persona può avere più di una macchina. Seguono le classi PersonToMany e CarToMany con le modifiche principali rispetto alle classi originarie.
PersonToMany
...
@Entity
public class PersonToMany {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
private String nome;
@OneToMany
private List<CarToMany> macchine;
public PersonToMany(){
macchine = new ArrayList<CarToMany>();
}
public List<CarToMany> getMacchine(){
return macchine;
}
public void addCarToMany(CarToMany carToMany){
if(!getMacchine().contains(carToMany)){
getMacchine().add(carToMany);
if(carToMany.getPersonToMany()!=null){
carToMany.getPersonToMany().getMacchine().remove(carToMany);
}
carToMany.setPersonToMany(this);
}
}
...Notiamo che nel momento in cui si aggiunge un riferimento ad un oggetto (addCarToMany()
PersonToMany
CarToMany
...
@Entity
public class CarToMany {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
private String nomeMacchina;
@ManyToOne
@Transient
private PersonToMany personToMany;
public CarToMany(){}
public PersonToMany getPersonToMany() {
return personToMany;
}
public void setPersonToMany(PersonToMany personToMany) {
this.personToMany = personToMany;
}
...Oltre all'annotazione @ManyToOne
@Transient
personToMany
MainToMany
...
CarToMany car1 = new CarToMany();
car1.setNomeMacchina("BatCar");
logJPA.jpaCreate(car1);
CarToMany car2 = new CarToMany();
car2.setNomeMacchina("BatMobile");
logJPA.jpaCreate(car2);
PersonToMany person = new PersonToMany();
person.setNome("Batman");
person.getMacchine().add(car1);
person.getMacchine().add(car2);
logJPA.jpaCreate(person);
...L'output su console generata dall'esecuzione del main
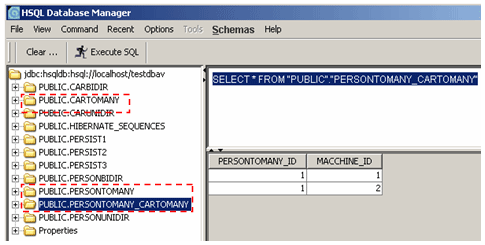
Osserviamo che sono tre le tabella generate, nell'immagine evidenziate dai rettangoli rossi tratteggiati. Due per le entità e una terza destinata a rendere persistente la relazione tra le due tabelle. Ecco spiegato perché è possibile evitare di rendere persistente l'attributo personToMany nell'entità CarToMany. Il riferimento è già memorizzato in un'altra tabella, inutile avere un altro campo nella tabella CARTOMANY.
Il popolamento delle relazioni avviene una volta sola in concomitanza con l'operazione di lettura delle query (operazione jpaRead()). Questo perché di default l'annotazione @OneToMany prevede una politica di fetch "EAGER", ossia le relazioni vengono caricate nella memoria Java una volta per tutte. L'alternativa, una strategia del tipo "LAZY", prevede che le entità associate vengano ricavate a runtime dal persistence provider.
È possibile evitare di avere una terza tabella per gestire le relazioni. Ad esempio è possibile memorizzare i riferimenti nella tabella CARTOMANY, semplicemente apportando le seguenti modifiche alla classe PersonToMany e rimuovendo l'annotazione @Transient della classe CarToMany.
...
@OneToMany(mappedBy="personToMany")
@OrderBy("name ASC")
private List macchine;
...Con queste modifiche il persistence provider eviterà di utilizzare una terza tabella e si limiterà a memorizzare i riferimenti nella tabella CARTOMANY.
Tuttavia, nella tabella PERSONTOMANY non è prevista una colonna per memorizzare il riferimento. Pertanto, una volta acquisiti dal database gli oggetti dell'entità PersonToMany, se si cercherà di far riferimento agli oggetti associati si otterrà un errore del tipo "user lacks privilege or object not found". Occorre pertanto fare attenzione a cosa si sta rendendo persistente e in che modo, onde evitare spiacevoli conseguenze.
In considerazione delle forme normali, dividere le informazioni sulle tre tabelle viste in precedenza costituisce una soluzione coerente, senza ridondanze e senza perdita d'informazioni, pertanto a meno di esigenze particolari è consigliabile utilizzare questa soluzione.
Relazione molti a molti
Se relazione è del tipo molti a molti, avremo due liste di oggetti in entrambe le entità. Ad esempio è possibile immaginare che una persona abbia diverse macchine e che una macchina possa appartenere a diverse persone. In questo caso avremo una classe Persona con una lista di auto e una classe Auto con una lista di persone.
Per rendere persistente questa relazione è possibile limitarsi ad annotare con @ManyToMany entrambe le liste.
Il persistence provider dovrebbe fornire una terza tabella per registrare le associazioni. Il comportamento in questo caso però sarà leggermente diverso dal previsto, in quanto l'effetto sarà quello di ottenere due tabelle per registrare le associazioni, le tabelle PERSONA_AUTO e AUTO_PERSONA.
È possibile evitare il problema con una seconda annotazione, l'annotazione @JoinTable:
//Classe Persona
@ManyToMany
@JoinTable(name=”Persona_Auto”)
private List auto;
...
//Classe Auto
@ManyToMany
@JoinTable(name=”Persona_Auto”)
private List persona;
...Classi Embeddable
Abbiamo affrontato le diverse forme assunte dalle relazioni dando praticamente per scontato la presenza di più di una tabella per effettuare il mapping relazionale. Ciò non è sempre necessario. È possibile far sì che le istanze di una classe siano immagazzinate come parte intrinseca di un'entità, attraverso una coppia di annotazioni:
| Annotazione | Descrizione |
|---|---|
| @Embeddable | Definisce che una classe deve essere considerata parte di un'entità proprietaria |
| @Embedded | Specifica un attributo persistente il cui valore è istanza di una classa embeddable |
C'è anche un terza annotazione, @ElementCollection, il cui compito è definire una collezione di istanze di un tipo base o eventualmente di una classe Embeddable.
È anche possibile avere un ID nella classe Embeddable, utilizzando l'annotazione @EmbeddedId il campo contribuirà insieme alla chiave dell'entità a formare una chiave composita.
L'esempio seguente mostra una classica relazione contenitore-contenuto, descrivibile con un'unica tabella anche partendo da due classi.
Contenitore
package embeddablepack;
import javax.persistence.Embedded;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Contenitore {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
private String nomeContenitore;
@Embedded
private Contenuto contenuto;
public Contenitore(){}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getNomeContenitore() {
return nomeContenitore;
}
public void setNomeContenitore(String nomeContenitore) {
this.nomeContenitore = nomeContenitore;
}
public Contenuto getContenuto(){
return contenuto;
}
public void setContenuto(Contenuto contenuto){
this.contenuto=contenuto;
}
public String toString(){
return "ID: " + getId() + " - Contenitore: " +
getNomeContenitore() + "n Contenuto:n" +
" " + getContenuto();
}
}Contenuto
package embeddablepack;
import javax.persistence.Embeddable;
@Embeddable
public class Contenuto {
private String nomeContenuto;
public Contenuto(){}
public String getNomeContenuto() {
return nomeContenuto;
}
public void setNomeContenuto(String nomeContenuto) {
this.nomeContenuto = nomeContenuto;
}
public String toString(){
return " - Contenuto: " +
getNomeContenuto();
}
}Main
package embeddablepack;
import java.util.List;
import JPALogic.LogicaJPA;
public class Main{
public static void main(String[] args) {
LogicaJPA logJPA = new LogicaJPA("testhsqldb");
Contenitore contenitore1 = new Contenitore();
contenitore1.setNomeContenitore("Scatola");
Contenitore contenitore2 = new Contenitore();
contenitore2.setNomeContenitore("Ciotola");
Contenuto contenuto1 = new Contenuto();
contenuto1.setNomeContenuto("Dado");
Contenuto contenuto2 = new Contenuto();
contenuto2.setNomeContenuto("Grano");
contenitore1.setContenuto(contenuto1);
contenitore2.setContenuto(contenuto2);
logJPA.jpaCreate(contenitore1);
logJPA.jpaCreate(contenitore2);
List<Contenitore> listaContenitori = logJPA.jpaRead(
"select t from Contenitore t").getResultList();
System.out.println("Oggetti resi persistenti:");
for(int i=0;i<listaContenitori.size();i++){
System.out.println(listaContenitori.get(i).toString());
}
logJPA.closeLogicaJPA();
}
}Osservando il main noteremo che una volta stabilita la relazione contenitore-contenuto, sarà necessario rendere persistente solo gli oggetti dell'entità contenitore. Segue un immagine che mostra lo stato del database dopo l'esecuzione del main.
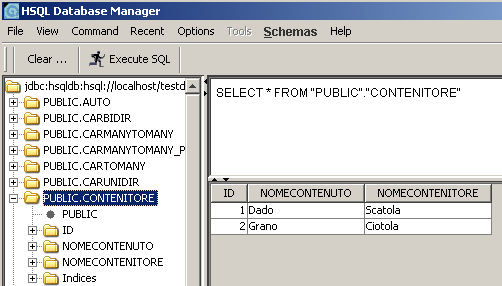
L'attenzione è posta nella tabella CONTENITORE e nelle tuple create dall'esecuzione del main. Il campo NomeContenuto, appartenente alla classe Embeddable, è divenuto parte integrante della tabella associata all'entità.
Classi Embeddable, considerazioni
Abbiamo visto il come, ma quando è conveniente utilizzare una classe Embeddable? Quando utilizziamo degli attributi logicamente connessi che potrebbero essere utilizzati in più di un'entità.
L'esempio classico è l'indirizzo. Invece di creare i relativi attributi in ogni entità che prevede un indirizzo, si può creare una volta per tutte una classe Indirizzo, renderla embeddable e includerla in ogni entità interessata. Ciò può significare un risparmio di tempo in fase di sviluppo.
Occorre però tener presente che è probabile che ciò vada in direzione opposta alla normalizzazione del database, esponendolo a ridondanze e al rischio di incoerenza. Occorre pertanto tener presente che la scelta di ricorrere a classi Embeddable non è una scelta automatica e la portata dell'impatto va ponderata di caso in caso.

