
Git è un sistema di controllo di versione creato da Linus Torvalds che sta diventando rapidamente uno dei più diffusi in circolazione, anche grazie all'adozione sempre maggiore di piattaforme quali github e bitbucket. Molti team di sviluppo, infatti, lo stanno preferendo ad altri sistemi collaudati, come SVN e CVS, entrambi opensource.
Git vs SVN, CVS, etc
Uno dei principali problemi ai quali va incontro un utente che si avvicina a GIT è quello di paragonarlo ad altri repository come SVN o CSV. A differenza di questi altri sistemi di versioning, però, la filosofia di GIT è leggermente diversa, e prima di iniziare ad utilizzarlo è consigliato apprendere per bene i concetti alla base di questo sistema.
SVN e CVS sono sistemi di controllo di versione centralizzati (Centralized Version Control Systems, CVCS), mentre GIT è un sistema di controllo di versione distribuito (Distributed Version Control Systems o DVCS).
Dove è il server?
Un sistema di controllo di versione centralizzato predispone la presenza di un singolo server che gestisce tutte le versioni dei file. Ciascun utente controlla i file mediante il proprio terminale.
In un sistema di controllo di versione distribuito, invece, ciascun client fa anche da server per se stesso e possiede una copia locale del repository.
In questo articolo ci concentreremo prevalentemente sull'utilizzo "client" di GIT, che è quello certamente più utilizzato al momento, anche grazie ad alcune piattaforme online già citate. Nulla vieta di installare il software su una propria macchina, ad esempio seguendo questo ottimo tutorial.
Come vengono memorizzati i dati?
SVN e CVS salvano l'informazione come una lista di cambiamenti apportati ai file e memorizzano le informazioni che essi mantengono come un insieme di file e le modifiche apportate su ciascuno di essi.
GIT, invece, considera i propri dati come una serie di istantanee (snapshot) di un mini filesystem. Ogni volta che l’utente effettua un commit, o salva lo stato del proprio progetto, fondamentalmente fa un'immagine di tutti i file presenti in quel momento, salvando un riferimento allo snapshot. Se alcuni file non sono stati modificati, GIT non li clona ma crea un collegamento agli stessi file della versione precedente.
lavorare offline
Altro aspetto molto interessante di GIT rispetto ai repository centralizzati, è la possibilità di lavorare anche in assenza di connettività con il server centrale. L’utente può lavorare sulla propria copia locale del repository e rendere pubbliche le modifiche quando il server ritorna disponibile.
GUI per Git
Quando GIT è installato sul sistema, è possibile effettuare tutte le operazioni da riga di comando, ma naturalmente sono disponibili numerosi client GUI free che è possibile utilizzare in base al sistema operativo.
Struttura di un progetto GIT
Un progetto GIT è strutturato in tre parti:
- Working dir o directory di lavoro che contiene i file appartenenti alla versione corrente del progetto sulla quale l’utente sta lavorando.
- Index o Stage che contiene i file in transito, cioè quelli candidati ad essere committati.
- Head che contiene gli ultimi file committati.
Inizializzazione di un progetto
É possibile inizializzare un nuovo progetto GIT in due modi:
- Definire un nostro progetto preesistente come GIT Repository.
- Clonare un repository Git esistente da un altro server.
Definire un nostro progetto preesistente come GIT Repository.
In questo caso occorre accedere alla directory del progetto e lanciare il comando init. Git creerà una nuova directory .git nella quale creerà i file di configurazione del repository.
Aggiunta e rimozione di file dal repository
Con le precedenti operazioni abbiamo soltanto indicato al sistema che la directory contiene un progetto GIT. Per aggiungere i file al repository (locale) è necessario lanciare il comando add seguito da un’espressione regolare che rappresenta l’elenco dei file da includere.
Infine occorre eseguire il commit dei file aggiunti.
Ecco un esempio nel quale inizializziamo il progetto, aggiungiamo tutti i file con estensione .c, il file config.properties ed il file readme ed effettuiamo il commit definendo una breve descrizione di ciò che stiamo versionando.
>> git init >> git add *.c >> git add config.properties >> git add readme >> git commit -m 'Il mio primo commit GIT'
Analogamente per rimuovere un file Hello.txt scriveremo ad esempio:
>> git remove Hello.txt
Clonare un repository Git esistente da un altro server.
In questo caso è sufficiente lanciare il comando clone seguito dall’url del repository remoto.
Tale operazione non è da confondere con il comando checkout di un repository di tipo SVN, poiché, in questo caso, verrà scaricato sul nostro sistema tutte le informazioni presenti sul server, comprese le informazioni storiche sui file e non solo la versione corrente.
Nell’esempio seguente cloniamo il progetto il cui indirizzo è git://github.com/myProject/myProject.git. Qualora non sia esplicitamente indicato, il progetto verrà scaricato nella directory corrente.
>> git clone git://github.com/myProject/myProject.git >> git clone git://github.com/myProject/myProject.git /myDirectory/myProject git clone myUser@git://github.com/myProject/myProject.git
Storico dei commit, il comando log
Mediante il comando log è possibile visualizzare l’elenco degli ultimi commit effettuati. Ciascun commit è contrassegnato da un codice SHA-1 univoco, la data in cui è stato effettuato e tutti i riferimenti dell’autore. Il comando, lanciato senza argomenti, mostra i risultati in ordine cronologico inverso, quello più recente è mostrato all'inizio.
Naturalmente sono disponibili numerosi argomenti opzionali utilizzabili con il comando log che permettono di filtrare l’output.
>> git log
Stato dei file, il comando status
Mediante il comando status, è possibile analizzare lo stato dei file. GIT ci indicherà quali sono i file modificati rispetto allo snapshot precedente e quali quelli già aggiunti all’area STAGE.
>> git status
Gestione dei Branch
Uno dei punti di forza di GIT è la gestione dei Branch. Spesso in un Team di sviluppo nasce l’esigenza di dover iniziare lo sviluppo di alcune nuove funzionalità che verranno poi riportate in produzione dove già gira una versione stabile del software. Durante la fase di sviluppo di queste nuove funzionalità, può emergere l’esigenza di dover sistemare (fix) un problema critico. E’ questo lo scenario ideale in cui i Branch vanno sfruttati.
Nel momento in cui parte un nuovo sviluppo ha senso creare un nuovo branch. In qualsiasi momento è possibile ripristinare il branch master. Terminato il fix è possibile fare il merge dei due branch e continuare a lavorare sulla funzionalità che avevamo sospeso per lavorare sul problema critico.
Creazione di un branch, il comando GIT checkout
Per creare un branch è sufficiente lanciare il comando checkout seguito dall’argomento –b e dal nome del branch che si desidera creare. Nel momento in cui un nuovo branch viene creato, GIT lo imposterà automaticamente branch corrente o working copy.
>> git checkout -b >> git checkout –b my_branch
Naturalmente, anche il Branch, così come per i file, può essere inviato o meno al repository remoto. Per farlo è sufficiente lanciare il seguente comando:
>> git push origin <nome del branch> >> git push origin my_branch
Come già anticipato, potrebbe verificarsi la necessità di ritornare a lavorare su un branch differente da quello attuale. Per poter switchare la working dir, è sufficiente utilizzare sempre il comando checkout seguito, in questo caso, semplicemente dal nome del branch.
>> git checkout <nome del branch> >> git checkout master
Eliminazione di un branch, il comando GIT branch
É possibile anche eliminare un branch che abbiamo precedentemente creato utilizzando il comando branch seguito dall’argomento -d (delete) ed il nome del branch da eliminare.
>> git branch –d <nome del branch> >> git branch –d my_branch
Merging di 2 branch, il comando GIT merge
Terminato lo sviluppo delle nuove feature, è necessario fondere i due branch. Tale operazione è disponibile utilizzando il comando merge. GIT importerà all’interno del branch attivo, il nuovo branch. Naturalmente occorre fare molta attenzione a quest’operazione poiché potrebbero verificarsi una serie di conflitti, tra uno o più file, che GIT non riesce autonomamente a risolvere, ed è necessario effettuare un merge manuale.
>> git merge <nome del branch> >> git merge master
Versionamento dei file sul repository remoto
Tutti i file di cui abbiamo fatto commit, quindi presenti nell’area HEAD, possono essere inviati al repository remoto utilizzando il comando push. É possibile definire anche il branch nel quale il nostro snapshot deve essere importato. Il branch di default è master ma naturalmente è possibile inviare le modifiche ad uno specifico branch definito sul server.
>> git push origin <nome del branch> >> git push origin master
Sincronizzazione con il repository remoto.
Per effettuare un aggiornamento dal server remoto, è sufficiente lanciare il comando pull che scaricherà tutte le informazioni sul nostro repository locale.
>> git pull
Riepilogo del flusso
Ora che abbiamo le idee un po' più chiare, riepiloghiamo i comandi base necessari per lavorare con GIT.
- Init – permette di inizializzare un progetto esistente.
- Log – permette di visualizzare un dettaglio relativo ai commit effettuati.
- Status – permette di visualizzare lo status dei file all’interno del repository locale.
- Add – permette di spostare uno o più file nell’index (o stage).
- Commit – permette di spostare uno o più file nell’HEAD.
- Push – permette di inviare uno o più file al repository remoto (in uno dei branch, di solito quello master).
- Pull – permette di scaricare in locale, le modifiche presenti sul server remoto inviate dagli altri utenti del repository.
- Checkout – permette di creare un branch oppure di switchare su uno dei prench disponibili
- Merge – permette di effettuare il merge di due branch.
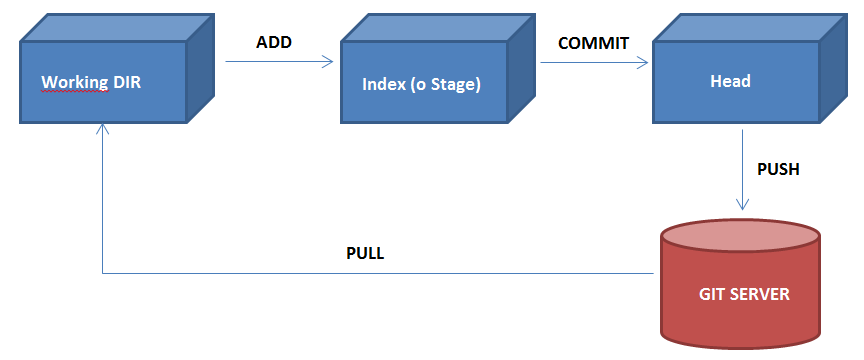
workflow di git
Approfondimenti su GIThub
Naturalmente sono disponibili anche altri comandi o argomenti ma in questo articolo abbiamo analizzato e descritto soltanto i principali che ci permettono, comunque di poter utilizzare a pieno le potenzialità di GIT.
Per chi fosse interessato ad approfondire la lista completa dei comandi GIT, rimandiamo alla nostra guida su github, o al sito gitref, che presenta un riepilogo visivo navigabile semplice ed efficace.
Esistono poi alcune cheatsheet molto efficaci:

