
Il Database Snapshot è una funzionalità introdotta da SQL Server 2005 per la creazione di copie in sola lettura dei propri database. Il sistema consente di creare più snapshot dello stesso database, ciascuno dei quali rappresenta una "fotografia" dello stato del DB al momento della definizione dello snapshot stesso.
Possiamo utilizzare uno snapshot come un normale database, sul quale effettuare solo operazioni in lettura, in altre parole, possiamo eseguire solo delle SELECT. Questa operazione risulta utile per la scrittura di report basati sui dati disponibili al momento della creazione dello snapshot. In caso di errori nel database di origine, ad esempio una cancellazione accidentale, è possibile ripristinare lo stato corrispondente al momento in cui è stato creato lo snapshot: la perdita dei dati è limitata agli aggiornamenti applicati al database dopo la definizione dello snapshot.
È importante precisare che gli snapshot, come vedremo meglio nel seguito, dipendono dal database di origine: se quest'ultimo diventa inaccessibile, non è possibile utilizzare uno snapshot per il suo ripristino: in altre parole, gli snapshot non possono essere utilizzati al posto di un tradizionale backup del database, che rimane quindi essenziale. Inoltre, a causa di questa dipendenza, gli snapshot devono sempre risiedere nella stessa istanza del DBMS che ospita la sorgente dati.
Gli snapshot, infine, sono supportati unicamente nell'edizione Enterprise di SQL Server e per la loro creazione è necessario ricorrere agli appositi comandi T-SQL, poiché non sono previste modalità di utilizzo tramite interfaccia grafica.
Come funziona uno snapshot
Un database snapshot viene definito a partire da un database sorgente e rappresenta la copia in sola lettura del suo contenuto al momento della creazione; per questo motivo non comprende un log delle transazioni.
I diritti di accesso ad uno snapshot sono ereditati da quelli che aveva il database di origine al momento della creazione dello snapshot; eventuali cambiamenti di diritti nella sorgente, applicati dopo la creazione dello snapshot, non modificano i privilegi di accesso a quest'ultimo.
Gli snapshot lavorano a livello di pagine di dati; il loro funzionamento è basato sulla cosiddetta tecnica copy-on-write. Nel momento della creazione, i file che costituiscono uno snapshot (chiamati file sparsi) non contengono effettivamente dati, quindi occupano solo una piccola quantità di spazio su disco: questo accorgimento permette di creare uno snapshot quasi istantaneamente, anche per database di grandi dimensioni. Quando, dopo la definizione di uno snapshot, si verifica un cambiamento in una pagina del database di partenza, SQL Server scrive il contenuto originale della pagina all'interno dello snapshot (occupando una certa posizione all'interno del file sparso corrispondente), in modo da conservare lo stato delle informazioni al momento della creazione dello snapshot. Ogni successiva modifica ai dati viene ignorata poiché, ai fini del mantenimento dello snapshot, è sufficiente tenere traccia solo del valore originale.
Ogni database snapshot contiene una struttura dati chiamata catalogo delle pagine modificate, in cui si tiene traccia delle pagine del database che sono state modificate dopo la creazione dello snapshot. Quando SQL Server scrive il contenuto originale di una pagina nello snapshot, aggiorna il catalogo segnalando che tale pagina è stata modificata. In questo modo, se si verifica un'ulteriore modifica alla pagina in questione, SQL Server si accorge che essa è già presente nel catalogo, quindi non scrive nulla nello snapshot.
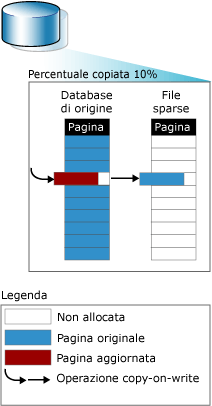
Questa struttura dati è usata anche per il recupero delle informazioni; quando si esegue una query su uno snapshot, il catalogo consente di sapere se una pagina è stata modificata dopo la definizione dello snapshot: se è cambiata, viene recuperato il valore contenuto nello snapshot, altrimenti sono usate le informazioni del database di origine.
Grazie al copy-on-write, negli snapshot vengono archiviate solo le versioni originali delle pagine che sono state modificate. Perciò, se si vuole ripristinare un database a partire da uno snapshot, è necessario prima eliminare tutti gli altri snapshot eventualmente definiti: poiché uno snapshot è definito per "differenze" rispetto allo stato del database di origine in un determinato momento, in seguito ad un ripristino di quest'ultimo le informazioni contenute nei vari snapshot non sarebbero più significative. Analogamente, non è possibile eliminare, scollegare o ripristinare un database (o i file che lo compongono) se su di esso sono stati definiti degli snapshot: prima eseguire queste operazioni, è necessario cancellare tutti gli snapshot relativi alla sorgente dati in questione.
Le prestazioni sono ridotte a causa del numero maggiore di operazioni di I/O sul database di origine derivanti da un'operazione di copia in scrittura per lo snapshot eseguita a ogni aggiornamento di una pagina.
Creazione e utilizzo di un database snapshot
Innanzi tutto, creiamo un semplice database contenente una rubrica telefonica, su cui eseguiremo le nostre prove, attraverso lo script Create.sql. Esso inserirà i dati nella tabella Contatti del database Rubrica.
| ID | Nome | Cognome | Indirizzo | Telefono | Cellulare | |
|---|---|---|---|---|---|---|
| 1 | Marco | Minerva | NULL | NULL | NULL | marco.minerva@gmail.com |
| 2 | Paolino | Paperino | Paperopoli | 555-54363 | NULL | NULL |
| 3 | Gastone | Fortunato | Paperopoli | 555-12300 | NULL | gastone@paperopoli.disney |
Come accennato all'inizio, per creare lo snapshot di un database si deve ricorrere a comandi T-SQL, poiché il Management Studio di SQL Server non offre un'interfaccia grafica per questa funzionalità. La sintassi da usare è comunque molto semplice, ed è simile a quella usata per creare un normale database:
CREATE DATABASE Snapshot_Name ON
( NAME = logical_file_name,
FILENAME = 'os_file_name' )
AS SNAPSHOT OF source_database;
È importante che il parametro logical_file_name coincida con il nome logico del file del database di cui si sta creando lo snapshot, altrimenti si otterrà un messaggio di errore. os_file_name, invece, è il file in cui si vuole effettivamente salvare lo snapshot.
Tornando al nostro esempio, per definire uno snapshot del database Rubrica si deve utilizzare il seguente comando T-SQL:
CREATE DATABASE RubricaSnap ON ( NAME = Rubrica, FILENAME = N'C:DBRubrica.snap' ) AS SNAPSHOT OF Rubrica;
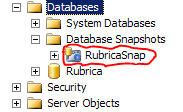
Questa istruzione crea uno snapshot di nome RubricaSnap e lo salva nel file C:DBRubrica.snap (la directory deve esistere prima della creazione dello snapshot). A questo punto, nel menu a sinistra del Management Studio appare un nuovo elemento, chiamato Database Snapshots, contenente tutti gli snapshot definiti nell'istanza corrente.
Se adesso proviamo ad eseguire una SELECT sul database originale ed una sullo snapshot:
-- Seleziona tutti i record della tabella Rubrica.Contatti USE Rubrica GO SELECT * FROM Contatti; GO -- Seleziona tutti i record della tabella RubricaSnap.Contatti USE RubricaSnap GO SELECT * FROM Contatti; GO
Otterremo gli stessi risultati, poiché lo snapshot rappresenta lo stato che aveva il database nel momento in cui è stato creato.
Proviamo ora a modificare il database originale, aggiungendo un record e modificandone uno esistente:
USE Rubrica
GO
INSERT INTO Contatti(Nome, Cognome, Indirizzo, Telefono, Cellulare, eMail) VALUES ('Mickey', 'Mouse', 'Topolinia', NULL, NULL, 'mickey@topolinia.disney');
GO
UPDATE Contatti SET eMail = 'paperino@paperopoli.disney' WHERE ID = 2;
GO
Eseguiamo nuovamente le query di selezione: noteremo che il database Rubrica è stato aggiornato, mentre RubricaSnap ha mantenuto le vecchie informazioni.
Un altro interessante utilizzo degli snapshot riguarda i database mirror. Poiché questi ultimi sono mantenuti sempre in recovering state, normalmente non sono accessibili agli utenti. È comunque possibile definire uno snapshot su questo tipo di archivi per poterne leggere i dati attraverso i normali comandi di SELECT, da utilizzare ad esempio per la creazione di report.
Infine, ricordiamo che, poiché lo snapshot è in sola lettura, qualunque istruzione di modifica dei dati in esso contenuti (INSERT, UPDATE o DELETE) causa un messaggio di errore.
Ripristino di un database
Poiché gli snapshot contengono solo le differenze rispetto al database di origine, per effettuare il ripristino di quest'ultimo utilizzando uno snapshot è necessario che la fonte dati di partenza sia accessibile. Durante l'operazione, tutte le pagine di dati contenute nello snapshot sovrascrivono le pagine corrispondenti nel database di origine.
La modalità con cui sono gestiti gli snapshot, inoltre, fa sì che il ripristino di un database "invalidi" il contenuto degli altri snapshot eventualmente presenti: in seguito ad un restore, infatti, le informazioni in essi contenute non risulterebbero più coerenti con il nuovo stato del database. Questo è il motivo per cui, prima di eseguire il ripristino di un database utilizzando uno snapshot, è necessario eliminare tutti gli altri snapshot creati in precedenza.
Detto questo, il ripristino vero e proprio si realizza con una semplice istruzione che, nel nostro esempio, risulta:
RESTORE DATABASE Rubrica FROM DATABASE_SNAPSHOT = 'RubricaSnap'
Durante il ripristino di un database a partire da uno snapshot, bisogna tenere conto dei seguenti aspetti:
- Tutti i cataloghi Full-Text definiti sul database di origine vengono eliminati, perciò devono essere ricreati manualmente al termine dell'operazione;
- Il log delle transazioni viene cancellato e ricreato, quindi non è possibile effettuare il restore del log ad un momento successivo a quello in cui è stato definito lo snapshot;
- Il database di origine e lo snapshot sono resi inaccessibili per tutta la durata dell'operazione, perciò non è possibile eseguire il ripristino se il database di origine o lo snapshot sono in uso.
Eliminazione di uno snapshot
La procedura di eliminazione di uno snapshot è identica a quella di un normale database di SQL Server:
DROP DATABASE RubricaSnap;
Eseguito il comando, le connessioni utente allo snapshot vengono chiuse e i file sparsi che lo compongono sono automaticamente eliminati dal file system.
Tutti i comandi T-SQL e le interrogazioni presentate sono disponibili nel file allegato.
Conclusioni
I database snapshot si rivelano un potente strumento, di SQL Server 2005 Enterprise Edition, per creare velocemente delle "istantanee" di un database. Sebbene non possano essere utilizzati come un normale backup, perché richiedono che la base di dati di partenza sia sempre disponibile, risultano utili in svariate circostanze. Ad esempio, prima di eseguire una serie di inserimenti bulk in un database, la creazione di uno snapshot garantisce la possibilità di ritornare velocemente alla situazione iniziale nel caso in cui si verifichi un problema durante l'inserimento (che magari ha portato all'incoerenza dei dati memorizzati).
Si deve comunque tenere presente che l'utilizzo di snapshot rallenta l'aggiornamento del database, perchè ogni operazione in scrittura nella sorgente determina anche la scrittura delle pagine modificate all'interno degli snapshot.
