
Nella gestione dei progetti software si ricorre sempre più spesso a metodologie consolidate, frutto di un'attenta analisi dei processi produttivi, in grado di massimizzare le performance del team di sviluppo senza sacrificare la qualità del prodotto finito. La visione generalmente condivisa al momento vede infatti lo sviluppo di un software più come un processo industriale che come un processo artigianale, caratterizzato quindi da una serie di linee guida e procedure alle quali attenersi durante tutte le fasi di lavoro.
Tuttavia, i prodotti software sono spesso più complessi da gestire rispetto a quelli "fisici", poiché essi richiedono una evoluzione costante e serrata nel tempo (basti pensare alla frequenza con cui una casa automobilistica rilascia un nuovo modello di vettura rispetto alla velocità con cui le software house rilasciano aggiornamenti). Sebbene questo fenomeno sia in parte giustificato dall'assenza (nel caso del software) di alcune fasi tipiche della produzione industriale che hanno un impatto diretto sia sui costi di produzione che sui tempi (assemblaggio, packaging, ecc.), è altrettanto vero che la complessità intrinseca di un qualunque prodotto dell'ingegno, software incluso, può portare all'introduzione di errori, difetti, malfunzionamenti, che rischiano di minare la stabilità del progetto. D'altro canto, data la pervasività del software a cui oggi assistiamo, è difficile concepire un prodotto industriale che non sia connesso, direttamente o indirettamente ad un progetto di sviluppo software (firmware, servizi, ecc). Tale convergenza giustifica ulteriormente l'adozione di processi unificati per lo sviluppo dei prodotti, software o meno.
Continuous Integration
Tra le pratiche di sviluppo più importanti vi è sicuramente la Continuous Integration (in breve, CI). Essa prescrive di integrare frequentemente le modifiche effettuate dagli sviluppatori sul codice sorgente, anche più volte al giorno, al fine di minimizzare i problemi causati da una fase di integrazione corposa. In questo scenario gli sviluppatori mantengono una copia condivisa dei codici sorgenti, aggiornandola ogni qualvolta una modifica è stata apportata.
Chiaramente questa metodologia necessita dell'adozione di un opportuno sistema di gestione di versione del codice, e Git al momento è uno dei più diffusi.
Sebbene integrare una piccola modifica sia in generale un compito meno oneroso rispetto all'integrazione di un intero modulo o feature, una frequenza di integrazione troppo alta potrebbe portare ad un cattivo uso delle risorse, soprattutto se questa operazione viene effettuata manualmente. Da questa osservazione è scaturita l'esigenza di automatizzare il processo di CI, dotando il team di sviluppo di strumenti che permettano una veloce integrazione ed una verifica automatica del codice sorgente, al fine di individuare tempestivamente eventuali problemi.
Continuous Delivery
Analogamente alla CI, la Continuous Delivery (in breve, CD), prescrive cicli di rilascio estremamente brevi. Piuttosto che rilasciare il software ad ogni major release, si distribuisce agli utenti una copia aggiornata frequentemente, al fine di garantire una migliore esperienza utente ed adattarsi rapidamente alle esigenze degli stessi. Spesso infatti lo sviluppo di una nuova feature scaturisce proprio dal feedback ricevuto dagli utenti.
Come si intuisce, una corretta implementazione della pratica CD richiede l'ausilio di opportuni strumenti di automazione. Ciò permette, da una parte, di sollevare gli sviluppatori dai compiti legati al deployment, e dall'altra di garantire una maggiore qualità del software rilasciato, riducendo al minimo il rischio di errori dovuti ad interventi manuali.
GitLab
GitLab è una piattaforma web sviluppata "intorno" al sistema di controllo di versione git. Essa integra una pletora di servizi concepiti per coprire l'intero ciclo di sviluppo del software, dall'analisi al rilascio, ponendo sempre il codice sorgente al centro di ogni attività.
Il modulo CI/CD integrato in GitLab ha avuto negli ultimi anni un rapido tasso di adozione, grazie alla sua relativa semplicità d'uso ed all'alto grado di personalizzazione offerto. A differenza di altre soluzioni, GitLab si adatta facilmente a qualunque progetto, indipendentemente dalla natura, dall'architettura o dai linguaggi con cui esso è sviluppato.
Pipeline CI/CD

GitLab automatizza le operazioni di CI e CD mediante la definizione di Pipeline Jobs push
Configurazione
Le operazioni da effettuare nei vari job, il numero di job da eseguire e la caratterizzazione stessa delle pipeline di CI e CD varia in base al progetto. Si può intuire facilmente, ad esempio, che il processo di CI per un'applicazione desktop comporti una fase di compilazione dei codici sorgenti, che potrebbe essere assente (in base alla tecnologia utilizzata) nel caso di un'applicazione web.
La descrizione delle pipeline e dei job viene pertanto effettuata direttamente sul repository, creando un file opportuno: .gitlab-ci.yml. L'aggiunta di un file con questo nome alla root del repository attiva automaticamente il modulo CI/CD di GitLab per quel repository.
Il file .gitlab-ci.yml utilizza, come si evince dall'estensione, la sintassi YAML. Si tratta quindi di un semplice file di testo nel quale descrivere le pipeline con un linguaggio apposito.
Ad esempio, supponendo di voler sviluppare un'applicazione desktop, e che essa venga compilata mediante il comando make, un semplice job di CI potrebbe essere descritto nel file .gitlab-ci.yml come segue:
build:
stage: build
script: make
artifacts:
paths:
- myprogram.exeIn questo esempio, il job di nome build make myprogram.exe
GitLab Runner
L'esecuzione dei comandi descritti nel file .gitlab-ci.yml non avviene direttamente sul server GitLab, ma attraverso dei servizi ad esso connessi: i Runner. Ciò permette di rendere le pipeline CI/CD di GitLab compatibili con qualsiasi linguaggio e piattaforma di sviluppo, poiché i comandi verranno eseguiti in un ambiente opportunamente configurato per questo scopo.
I runner possono essere macchine (fisiche o virtuali) o container Docker. Essi eseguono un servizio, GitLab Runner, in grado di ricevere comandi dal server GitLab al quale è associato. Quando GitLab richiede l'esecuzione di un job, il runner effettua un fetch del repository ed esegue i comandi indicati per quel particolare job. Al termine dell'esecuzione, il runner riporta il risultato dell'operazione al server GitLab, il quale si occuperà di richiedere l'esecuzione di un altro job nella pipeline e di registrare lo stato di avanzamento dell'esecuzione.
In casi più complessi è possibile eseguire più job in parallelo se si dispone di più runner compatibili. Si pensi ad esempio allo sviluppo di un'applicazione multipiattaforma, per Windows e macOS. La compilazione degli eseguibili per le due piattaforme dovrà avvenire su due runner diversi, ciascuno configurato con gli opportuni strumenti di sviluppo. Pertanto, è possibile eseguire i due job di compilazione contemporaneamente.
Nel caso in cui si utilizzi il servizio ospitato sul sito gitlab.com, è possibile utilizzare dei runner condivisi sotto forma di container docker. GitLab mette a disposizione una pletora di immagini docker preconfigurate con il servizio runner, ciascuna adatta ad un particolare compito. Ad esempio, l'immagine docker gcc viene utilizzata per le build di progetti C/C++ per Linux. Per utilizzare una particolare immagine Docker, è sufficiente indicare il nome dell'immagine all'inizio del file .gitlab-ci.yml. Ad esempio:
image: gcc
build:
stage: build
script: make
artifacts:
paths:
- myprogram.exeMonitoraggio
Ogni esecuzione di una pipeline viene registrata, accompagnata da importanti informazioni quali l'identificativo del commit che ha generato l'operazione, il nome dello sviluppatore che ha effettuato il commit, la data e la durata dell'esecuzione, ed infine se la pipeline è state eseguita con successo o si sono verificati degli errori.
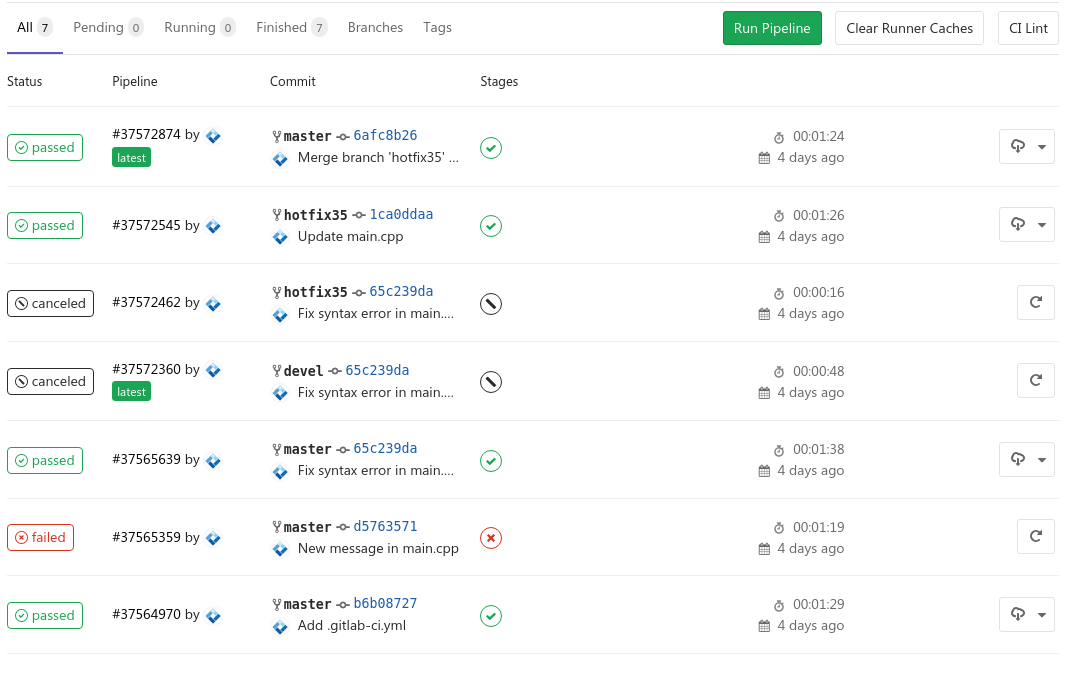
Ciò permette di identificare tempestivamente ogni problema di integrazione delle modifiche, consentendo un aumento delle prestazioni generali del team e della capacità di rilasciare aggiornamenti in tempi brevi.
