
Lo sviluppo di applicazioni Web è una vera e propria art e non solo per quanto riguarda l'aspetto grafico o gli aspetti legati all'usabilità e all'accessibilità. Il cambiamento della percezione del "sito Web" con l'introduzione del concetto di "applicazione Web" e l'evoluzione tecnologica che ne è conseguita, hanno portato ad applicare le metodologie più avanzate di sviluppo delle applicazioni anche a quest'ambito.
Queste metodologie e tecniche ci permettono di costruire applicazioni Web ad un livello prima inimmaginabile, passando per modelli di sviluppo orientati agli oggetti, che fino a ieri, vedevano come campo d'utilizzo solamente le applicazioni desktop.
ASP.NET (e il .NET Framework) è un esempio di piattaforma per lo sviluppo Web interamente basata sul paradigma ad oggetti. Grazie ad esso siamo in grado di progettare applicazioni Web "a strati", dove ad ogni livello concettuale corrispondono azioni ben precise, legate tra loro per il raggiungimento di scopi comuni. Possiamo pensare ad una applicazione come all'intergrazione di componenti a se stanti che comunicano tra loro.
Seguendo questa filosofia, sono nate le applicazioni Web a 3 livelli.
Si fa riferimento a siti Web che vedono divisi tra loro i meccanismi di presentazione, di gestione concettuale dei dati o dei meccanismi di "business", e di accesso fisico al database. Questo approccio favorisce il lavoro in team, in cui ciascuno (o ciascun gruppo di sviluppatori) cura componenti particolari, che saranno assemblati sono in una fase avanzata dello sviluppo.
Un modo di pensare che rimpiazza in modo vincente la più classica programmazione "spaghetti like" che vede markup, logica applicativa e codice per l'accesso ai dati inseriti nel medesimo file.
Come abbiamo annunciato è possibile suddividere gli strati necessari alla produzione del software in almeno 3 livelli:
- Data Access Layer (DAL) È il livello di interazione con la base di dati legata al sito, dove si effettua fisicamente la connessione e si eseguono query di selezione, inserimento, aggiornamento o cancellazione. Il grado di importanza di questo strato dovrebbe essere chiaro, è in questo strato che si determina l'efficienza della conservazione e della consultazione dei dati.
- Business Logic Layer (BLL) È il livello di descrizione delle entità logiche che descrivono i processi di business utilizzati all'interno dell'applicazione. Tali entità sono delle classi vere e proprie, con attributi e metodi utili a rappresentare la logica applicativa del proprio sito Web. All'interno di questo strato vengono definite tecniche di gestione dei dati come, ad esempio, il loro inserimento nella cache della pagina o eventuali codifiche o decodifiche. È quindi questo il livello che è in diretta collaborazione con l'interfaccia utente.
- User Interface (UI) È lo strato di presentazione dell'applicazione. In parole povere è qui che si stabilisce "ciò che si vede", a questo livello viene definita la rappresentazione dei dati e l'interfaccia utente. È qui che usiamo in modo importante pagine e controlli Web e i dati che rappresentano sono forniti dai livelli inferiori.
L'applicazione di questo paradigma ci permette di lavorare meglio in team e di scrivere applicazioni più robuste, che tipicamente offrono maggior scalabilità e facilità nella manutenzione.
Il Domain Model
Oltre a suddividere il problema in strati possiamo creare un modello del dominio dell'applicazione, ovvero un insieme di classi che servono a rappresentare le entità coinvolte, le relazioni tra loro e i comportamenti.
Questo modello, il "Domain Model" può essere rappresentato da un diagramma di classi concreto. Ogni livello comunica con gli altri attraverso la definizione di alcune particolari classi inserite all'interno dell'applicazione, che fungono da collante tra uno strato e l'altro. Si tratta di entità logiche che rappresentano i dati che dovranno essere poi gestiti dai livelli sopra descritti. Quindi nel caso in cui volessimo costruire un sito internet che contenga un blog, farebbero parte di questo gruppo le classi Post, Category e Author, ognuna delle quali dovrà esporre le proprietà utili a contenere le informazione necessarie all'applicazione.
Nota: Visual Studio offre un designer apposito in grado di visualizzare tutti gli oggetti appartenenti a questo gruppo di classi e di permettere all'utente la modifica di questi oggetti in maniera del tutto visuale; uno strumento questo, molto utile per quanto riguarda questo aspetto dello sviluppo di applicazione software.
Spesso e volentieri queste classi tendono a mappare completamente le tabelle presenti all'interno del database legato all'applicazione; questa tecnica, detta Object Relational Mapping (ORM), è molto in voga in questo momento e vede la sua applicazione pratica nel progetto open-source Nhibernate e nel futuro "Entity Framework" di Microsoft.
Una seconda tecnica invece, come oggetti utili alla comunicazione tra questi livelli, utilizza le classi base per il trasporto delle informazioni del namespace System.Data, come per esempio le classi DataSet e DataTable. Questo approccio, totalmente differente da quello del Domain Model, porta allo sviluppatore sia una certa velocità di sviluppo, ma anche la perdita di interessanti tecniche come la serializzazione dei dati e la tipizzazione, con conseguente calo delle performance di tutto il sito.
I tre livelli in pratica
Passiamo all'utilizzo pratico di questa metodologia nello sviluppo di un piccolo blog. Un sito Web del genere si presta infatti perfettamente allo sviluppo secondo un'architettura a tre livelli, in quanto tutti i dati devono essere salvati utilizzando una fonte di dati (database o file XML che sia) e successivamente presentati all'utente attraverso un'interfaccia chiara, che permetta ad esempio, la navigazione dello storico. Inoltre, deve essere presente una gestione logica dei dati che permette allo sviluppatore di dividere i contenuti in categorie, e presentarli all'utente in base a criteri temporali (archivio mensile, settimanale o giornaliero) o in base a singole parole chiave (meccanismo dei tag).
Partiamo quindi, con l'aggiunta di 4 nuovi progetti alla nostra soluzione di partenza in Visual Studio:
- Sito Web (User Interface)
- Libreria di classi Peppe.Common (Domain Model)
- Libreria di classi Peppe.BLL (Business Logic Layer)
- Libreria di classi Peppe.DAL (Data Access Layer)
La library contenente le classi del Domain Model contiene le definizioni delle entità logiche Post e Category, che rappresentano i principali oggetti utilizzati all'interno del blog, assieme alle classi di collezione PostCollection e CategoryCollection.
Le entità Post e Category derivano direttamente da una classe padre, definita come classe astratta, che fornisce le funzionalità di base comuni a tutte le entità in gioco nella nostra applicazione Web. Nel nostro caso è la classe EntityBase che fornisce a tutte le sue classi figlie la proprietà ID e un costruttore utile a valorizzare tale proprietà. Questo meccanismo di ereditarietà è chiaro nel diagramma delle classi.
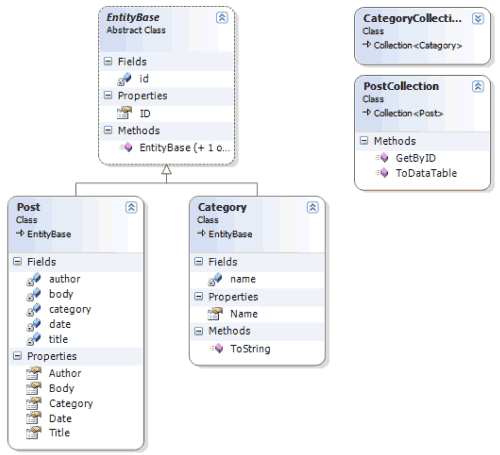
In dettaglio, la classe Post conterrà tutte le informazioni per rappresentare un generico messaggio del nostro Web log, come titolo, data di pubblicazione, autore e categoria. La classe Category invece, conterrà semplicemente un identificativo e un nome per la rappresentazione di una singola categoria.
Le classi di collezione invece, derivano direttamente dalla classe Collection (del namespace System.Collections.ObjectModel) che permette, sfruttando il meccanismo dei Generics di .NET 2.0, di creare una collezione di oggetti tipizzati con metodi e proprietà di base già funzionanti.
Noi abbiamo poi la possibilità di aggiungere funzionalità più avanzate alle nostre collezioni aggiungendo nuovi metodi. Per esempio, abbiamo qui il codice del metodo ToDataTable, che trasforma la collezione di oggetti in questione in un oggetto di tipo DataTable (vedremo in seguito in che contesto verrà utilizzato questo particolare metodo).
namespace Peppe.Common
{
public class PostCollection : Collection<Post>
{
public DataTable ToDataTable()
{
DataTable dt = new DataTable();
dt.Columns.Add("ID", typeof(int));
dt.Columns.Add("Title", typeof(string));
dt.Columns.Add("Body", typeof(string));
dt.Columns.Add("Category", typeof(string));
dt.Columns.Add("Date", typeof(DateTime));
dt.Columns.Add("Author", typeof(string));
foreach (Post p in Items)
{
DataRow row = dt.NewRow();
row["ID"] = p.ID;
row["Title"] = p.Title;
row["Body"] = p.Body;
row["Category"] = p.Category.ToString();
row["Date"] = p.Date;
row["Author"] = p.Author;
dt.Rows.Add(row);
}
return dt;
}
}
}
È molto importante notare che questa libreria di classi deve essere aggiunta come riferimento in tutti gli altri progetti che abbiamo aggiunto alla nostra soluzione Visual Studio .NET 2005.
Nella seconda parte dell'articolo esamineremo in dettagli la composizione dei tre livelli dell'applicazione.
Accesso ai dati
Una volta definito il Domain Model, passiamo al gradino fondamentale della nostra applicazione: l'accesso ai dati. Questo è il livello in cui stabiliamo le connessioni con le basi di dati, è l'unico livello in cui mettiamo in piedi un'interazione esterna all'applicazione.
Risulta molto utile costruire meccanismi di accesso ai dati svincolati dal tipo di database cui si vuole accedere in modo tale da rendere la nostra applicazione il più flessibile possibile, pronta quindi ad eventuali cambiamenti di DBMS nel corso del tempo. Per questo ci vengono in aiuto le classi del namespace System.Data.Common, che attraverso il design pattern detto "Factory Method", offrono un meccanismo di accesso alla base di dati completamente astratto.
Un esempio di tale tecnica, ci viene dato dal metodo GetPost(), che seleziona un singolo post inserito all'interno del nostro blog dato il suo identificatore:
public Post GetPost(int id)
{
Post post = new Post();
DbProviderFactory factory = DbProviderFactories.GetFactory(ConnectionHelper.GetProviderName());
using (DbConnection conn = factory.CreateConnection())
{
conn.ConnectionString = ConnectionHelper.GetConnectionString();
using (DbCommand cmd = factory.CreateCommand())
{
cmd.CommandText = "SELECT Posts.Title, Posts.Body, Posts.Author, " +
"Posts.Date, Posts.CategoryID, Categories.Name " +
"FROM Posts INNER JOIN Categories ON " + "Posts.CategoryID = Categories.ID "+
"WHERE Posts.ID = @id";
cmd.Connection = conn;
DbParameter param = factory.CreateParameter();
param.Value = id;
param.ParameterName = "@id";
param.DbType = DbType.Int32;
cmd.Parameters.Add(param);
conn.Open();
DbDataReader reader = cmd.ExecuteReader();
while (reader.Read())
{
post.ID = id;
post.Author = String.Format("{0}", reader["Author"]);
post.Body = String.Format("{0}", reader["Body"]);
Category cat = new Category();
cat.ID = Convert.ToInt32(reader["CategoryID"]);
cat.Name = String.Format("{0}", reader["Name"]);
post.Category = cat;
post.Date = Convert.ToDateTime(reader["Date"]);
post.Title = String.Format("{0}", reader["Title"]);
}
reader.Close();
}
}
return post;
}
All'interno di questo metodo non vi è alcun riferimento al tipo di database utilizzato, le informazioni riguardo il tipo di provider da utilizzare per la connessione e il nome del database vengono lette direttamente dal file di configurazione del'applicazione (Web.config).
<connectionStrings>
<add name="strConn" connectionString="DataSource=.SQLEXPRESS;AttachDbFilename=|DataDirectory|Database.mdf;Integrated Security=True;User Instance=True"
providerName="System.Data.SqlClient"/>
</connectionStrings>
In questo modo abbiamo definito che la nostra base di dati dovrà essere un database di SQL Server 2005.
Ora che abbiamo deciso la tecnica con cui accedere ai dati, dobbiamo definire tutti i metodi da utilizzare all'interno dell'applicazione, in modo tale da farci ritornare i dati che ci interessano. Siccome stiamo parlando di un blog, per fornire le funzionalità pensate si è deciso di implementare i seguenti metodi:
| classe PostManager | classe categoryManager |
|---|---|
GetPost(int id)GetAllPosts()GetLast5Posts()GetPostsByCategory(int categoryID)GetPostsByTag(string tag)Insert(Post p)Delete(Post p)Update(Post p)
|
GetCategory(int id)GetAllCategories()Insert(Category c)Update(Category c)Delete(Category c)
|
L'implementazione di questi metodi verrà omessa per ovvie questioni di spazio, ma è presente all'interno del codice sorgente dell'applicazione in allegato all'articolo.
Logica di business
Una volta create quindi, le entità logiche di rappresentazione dei dati e le classi di accesso a database, dobbiamo definire le logiche con cui trattare questi dati prima di fornirli all'utente in maniera definitiva. Questo livello permette la comunicazione tra l'accesso ai dati e l'interfaccia utente, che descrive come gli oggetti definiti all'interno del Domain Model interagiscono fra di loro e che applica una gestione intermedia dei dati, manipolandoli seguendo tecniche ben definite per poi offrirli in visualizzazione.
Per esempio, in questo strato, abbiamo la possibilità di codificare le informazioni, di decidere quali di queste devono essere visualizzate in base a fattori esterni o, nel caso di un'applicazione Web, di gestire l'interazione con la memoria cache del server.
Nel nostro esempio, si è deciso infatti di utilizzare delle classi intermediarie per fare in modo di salvare le informazioni prelevate dalla base di dati, all'interno della cache. Si è dovuto quindi creare un metodo per ognuna delle operazioni esposte dal livello di accesso ai dati, per poi decidere se fornire le informazioni alla User Interface direttamente dal database o dalla memoria cache del server.
Vediamo quindi come è stato sviluppato il metodo che preleva un singolo post dato il suo identificatore:
namespace Peppe.BLL
{
public static class Posts
{
private static readonly Cache cache = HttpContext.Current.Cache;
public static Post GetPostByID(int id)
{
string cacheKey = "Post" + id.ToString();
object o = cache[cacheKey];
if (o != null)
return o as Post;
else
{
Post p = new PostManager().GetPost(id);
cache[cacheKey] = p;
return p;
}
}
//...
}
}
Come potete vedere, se non sono già presenti le informazioni all'interno della cache, vengono chieste al Data Access Layer e poi inserite in memoria. I due livelli sono in grado di comunicare direttamente tra di loro grazie all'utilizzo come tipi di ritorno delle classi appartenenti al Domain Model.
L'utilizzo di questa tecnica permette di miglioraree le performance dell'applicazione Web, ma nulla ci vieta di applicare in questo strato le logiche aziendali di gestione dei dati.
Presentazione
Lo sviluppo del livello di presentazione, quindi delle pagine e dei controlli Web della nostra applicazione, è l'ultimo passo da compiere nella costruzione di un sito a tre livelli e, nella maggior parte dei casi, è anche la parte più veloce da fare in quanto il "grosso" si può dire che è già stato fatto nei due livelli inferiori.
Per procedere all'inserimento di un nuovo post all'interno del nostro blog basta scrivere:
protected void OnInsert(object sender, EventArgs e)
{
Post post = new Post();
post.Author = "Marchi Giuseppe";
post.Body = txtBody.Text.Replace("rn", "rn<br />");
post.Category = Categories.GetCategoryByID(Int32.Parse(ddlCategories.SelectedValue));
post.Date = DateTime.Now;
post.Title = txtTitle.Text;
new PostManager().InsertPost(post);
}
Mentre per quanto riguarda la visualizzazione dei messaggi, non dobbiamo far altro che utilizzare un oggetto di tipo DataSource per la lettura dei dati dalle nostre classi di business e un oggetto di tipo Data-Bound per la rappresentazione grafica di tali informazioni.
<asp:Repeater ID="rep" runat="server" DataSourceID="posts">
<ItemTemplate>
<h2><%# Eval("Title") %></h2>
<p><%# Eval("Body") %></p>
</ItemTemplate>
</asp:Repeater>
<asp:ObjectDataSource ID="posts" runat="server"
SelectMethod="GetLast5" TypeName="Peppe.BLL.Posts" />
In questo caso risulta importante notare che il controllo di tipo ObjectDataSource preleva le informazioni richiamando la classe Posts del livello di Business Logic e non una classe del livello di accesso ai dati, in questo modo alla prima richiesta della pagina viene fatta una selezione dal database, ma già dalla seconda verranno lette le informazioni dalla cache del server, in conformità con quanto deciso nella nostra logica di business.
Allo stesso modo, il controllo di tipo Repeater è in grado di effettuare il binding dichiarativo direttamente sulle proprietà della classe Post, singolo oggetto della collezione che ritorna il metodo GetLast5(). Saranno poi i livelli sopra descritti a fare tutto il resto del lavoro.
Altra tecnica interessante può essere quella di legare il livello di business logic ad un server control personalizzato, senza utilizzare sempre oggetti di tipo DataSource. Nell'esempio scaricabile si è deciso di creare un oggetto che derivi dall'oggetto Calendar di ASP.NET 2.0 per visualizzare in quali giorni sono stati inseriti dei messaggi all'interno del blog.
Non si è dovuto far altro che creare una proprietà "DataSource" da supporto per il binding dei dati:
public object DataSource
{
get { return dataSource; }
set { dataSource = value; }
}
richiamare le informazioni all'interno del metodo OnInit del nostro controllo:
protected override void OnInit(EventArgs e)
{
dataSource = Posts.GetAll().ToDataTable();
base.OnInit(e);
}
effettuare l'overload del metodo
OnDayRender
per modificare la visualizzazione del calendario in base alle informazioni lette dalla fonte di dati:
protected override void OnDayRender(TableCell cell, CalendarDay day)
{
DataTable posts = (DataTable)dataSource;
DataView view = new DataView(posts);
DateTime time = day.Date.AddDays(1);
view.RowFilter = String.Format("{0} >= #{1}# and {0} < #{2}#",
"Date", day.Date.ToString("MM/dd/yyyy"),
time.ToString("MM/dd/yyyy"));
if (view.Count > 0)
{
if (SelectedDate != day.Date)
{
cell.BorderStyle = BorderStyle.Solid;
cell.BorderWidth = new Unit("1px");
cell.BorderColor = ColorTranslator.FromHtml("#C0C0C0");
}
}
else
{
day.IsSelectable = false;
}
base.OnDayRender(cell, day);
}
Il risultato a livello di presentazione del controllo è veramente d'effetto, soprattutto se si considera che è stato ottenuto con uno sforzo minimo.
Conclusioni
Dividere l'applicazione in più livelli logici aumenta il lavoro, ma i vantaggi in termini di manutenzione dell'applicazione e di prestazioni, sono notevoli. Basti pensare che se abbiamo bisogno di cambiare sistema di database, è sufficiente modificare uno solo dei livelli dell'applicazione.


